Getting started (legacy)
Welcome to Wrangler!
To get yourself comfortable with CloverDX Wrangler, we recommend you take the following path to learn the Wrangler basics so that you can later explore additional functionality on your own:
-
Start with the Wrangler tutorial if you are on CloverDX 7.2 or newer.
-
Use the steps reference part of this documentation to understand each transformation step in detail.
-
Start your own project!
-
Start with a quick introduction video How Wrangler works (2 minutes). This video works best for CloverDX 7.1 or older.
-
You can also watch a 15-minute Quick tutorial that will guide you through a sample task.
How Wrangler works (video)
This video provides a brief overview of what Wrangler is and what you can do with it.
Quick tutorial (video)
We highly recommend you follow this quick tutorial before you start exploring on your own. This video is most suitable for CloverDX 7.1 or older. With CloverDX 7.2 and introduction of Clover AI Assistant, we recommend you start with the tutorial.
The video will walk you through building your first Wrangler job and explain the core principles in detail. You can then read additional details in the rest of this guide.
Formulas and calculations
If you are using CloverDX 7.2 or newer, please continue reading here.
Formulas can be entered in the following steps:
Formulas are also used in step and group conditions. For more information, see Step and group conditions.

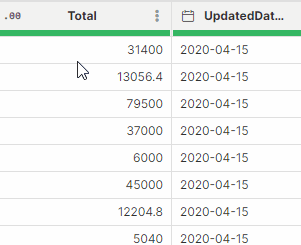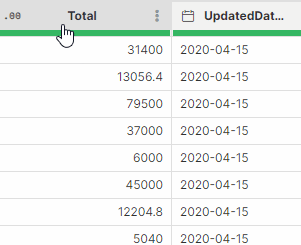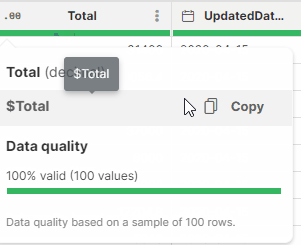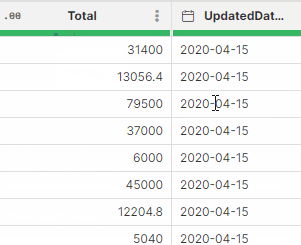
In your formulas, you will need to specify the column(s) that you want to work with. A column is referenced by its technical column name - a name that is automatically created by Wrangler by stripping various special characters from the column label (e.g., a column with the label Invoice amount (USD) will have the technical name $Invoice_amount_USD). Technical column names always include the $ sign to make it easy to distinguish from other names that can appear in formulas.
To find and easily copy the technical column name, hover over a column header.
Technical column names are case-sensitive and need to be entered in the exact form as displayed. If you mistype a technical column name, you will get an error like this:
Error: Field '$invoice_amount_USD' does not exist in record 'invoices_csv'
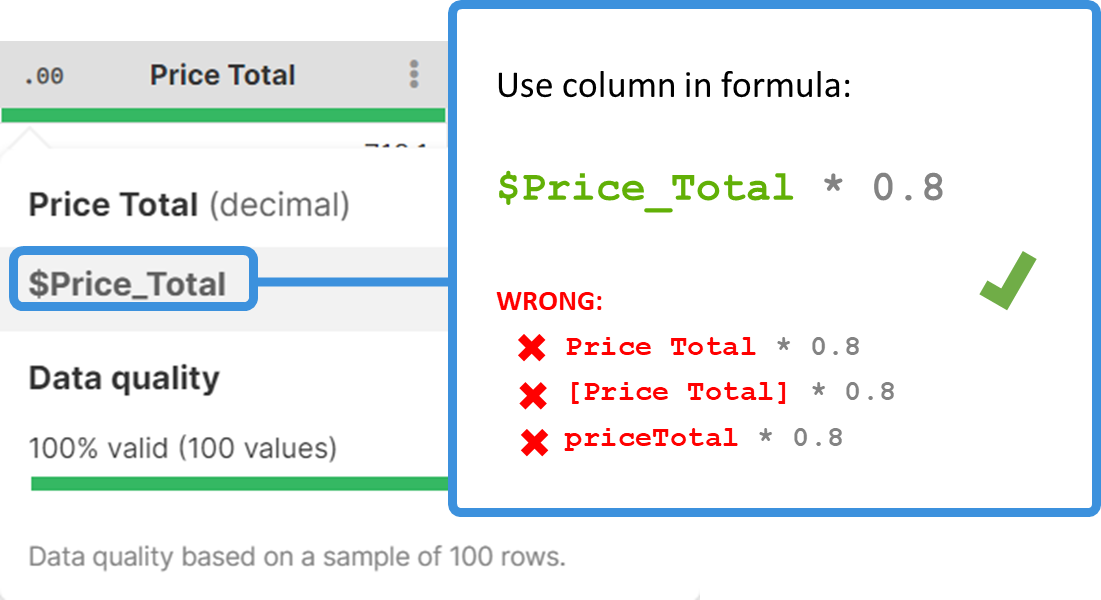
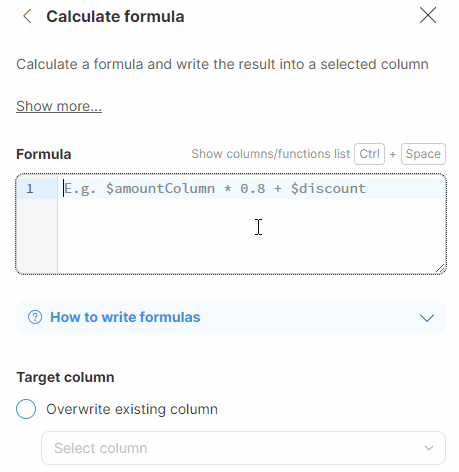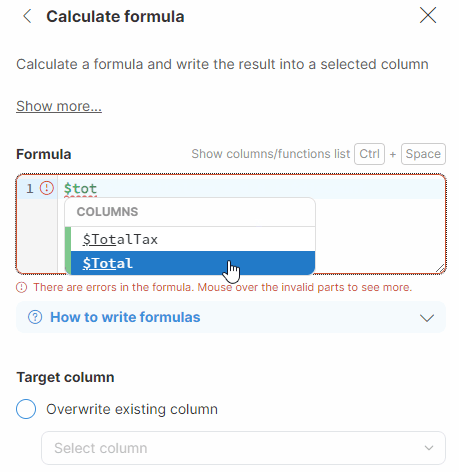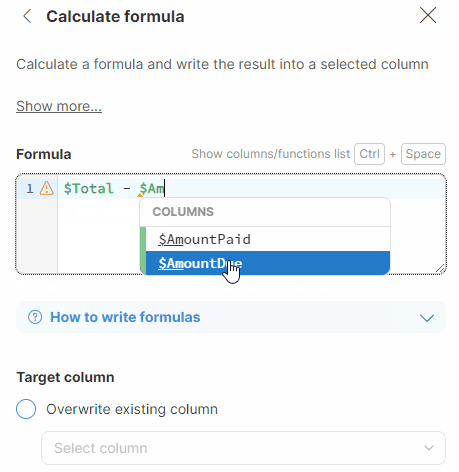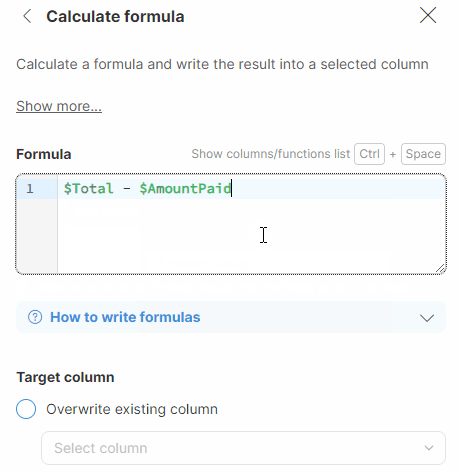
You can also use the autocomplete functionality in Formula Editor, which automatically displays a list of all existing technical column names after you type the $ character. Alternatively, you can display the list of all technical column names and all available functions by using the Ctrl + Space shortcut.
Comparing values
The operators below can be used to compare values; however, note that that you can only compare values with the same data types.
| Operator | Description |
|---|---|
|
Equal to (double =) for all data types |
|
Not equal to |
|
Greater than |
|
Greater or equal |
|
Less than |
|
Less or equal |
Important information to bear in mind:
-
When working with decimals, you need to specify all the decimal places in the unformatted form in your formula. Decimal values can also only include decimal points; commas as decimal separators are not supported. See How can I work with precise numbers (including currency)? for more information.
-
When working with dates, make sure to enter them in the
YYYY-MM-dd format(orYYYY-MM-dd HH:mm:sswhen using full date and time). See How do date values work? for more information. -
When working with strings, the values need to be enclosed in double or single quotes. See How can I use strings? How to work with text data? for more information.
-
When working with empty values, see How do I work with empty values? What’s the difference between null and empty? for more information.
| Example | Explanation |
|---|---|
|
Returns |
|
Returns |
|
Returns |
|
Returns |
|
Often the best option. |
|
Returns |
|
Returns |
Calculations and functions
| Operator | Description | Example formula | Result |
|---|---|---|---|
|
Add numbers |
|
|
|
Concatenate strings |
|
|
|
Subtract numbers |
|
|
|
Multiply numbers |
|
|
|
Divide integers |
|
500 if |
|
Divide decimals |
|
500.5 if |
|
Modulo (remainder after division) |
|
|
When working with columns that include numbers (integers or decimals), you can use mathematical operators.
Note: With the exception of the + operator, these operators cannot be used for any other data types than integers or decimals. If you, e.g., attempt to use the - operator when working with date columns, you will get the following error:
Error: Operator '-' is not defined for types: 'date' and 'date'
The + operator can be used as a concatenation function to join values from multiple columns when working with string values (or a combination of string and other data types values; however, in such a case a use of other functions to set the desired format might be needed: more information on this can be found in the Functions section). You can also optionally insert a space or any other characters in between the values.
Example: You want to join invoice numbers and status values and want to enter the & symbol in between, preceded and followed by a space:
$InvoiceNumber + ' & ' + $Status
For more complex cases, you can use one of our built-in functions. The autocomplete feature in Formula Editor suggests relevant functions as you type. Alternatively, you can use the CTRL + Space shortcut to display the list of available column names (marked in green, starting with the $ sign) and functions (marked in purple). When inserting a function, placeholders for its parameters are automatically included, providing guidance for formula construction. Substitute these placeholders with the appropriate data to build your formula.
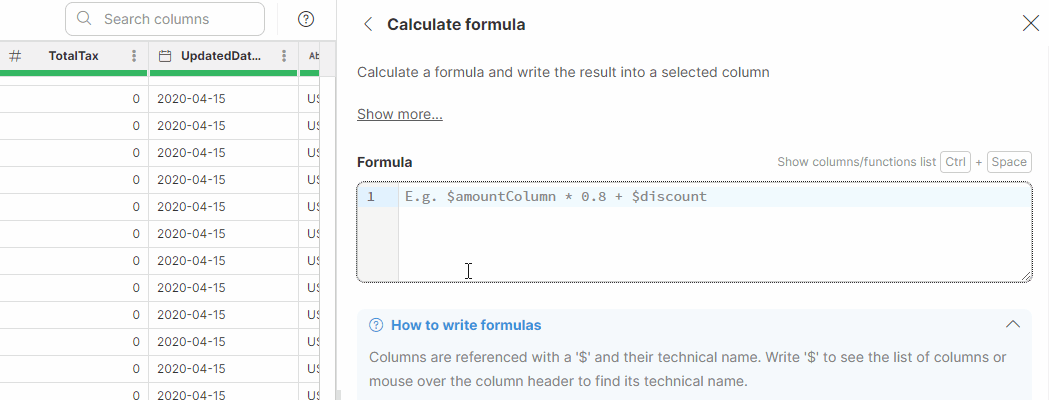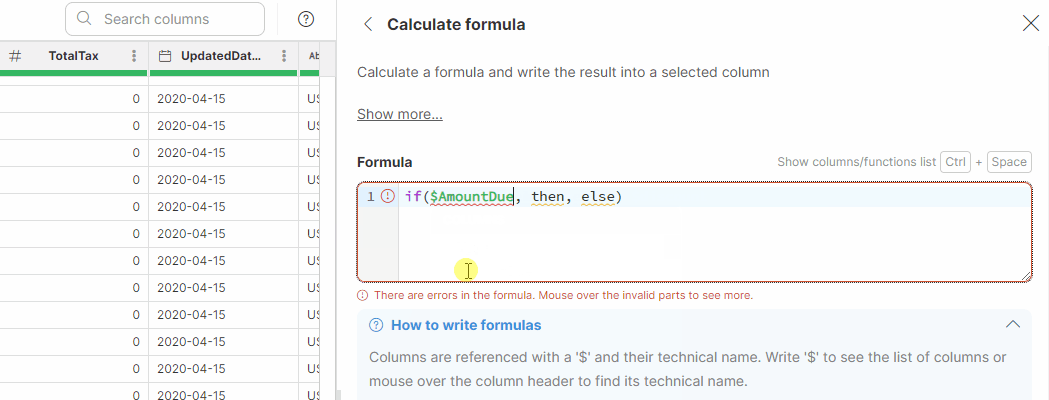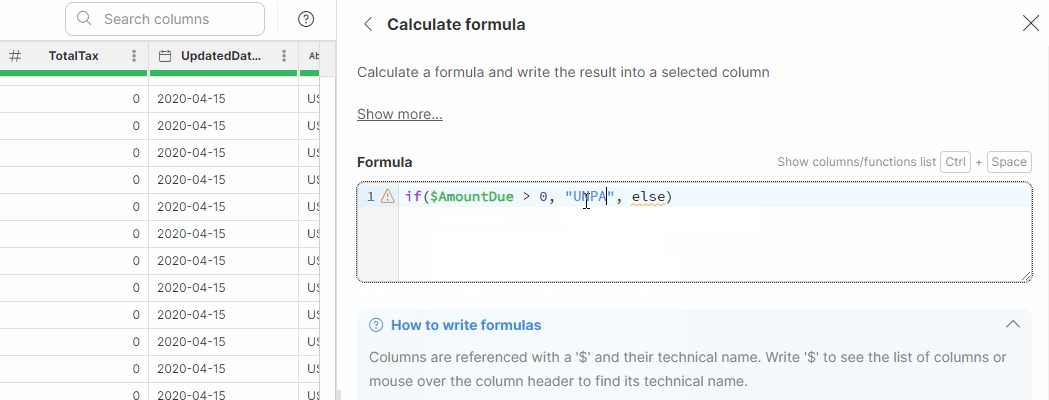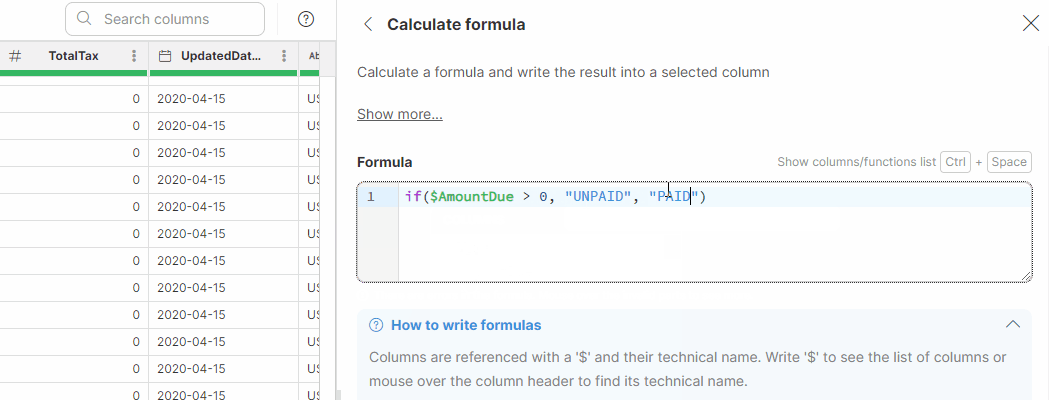
| Function | Description | Example formula | Result |
|---|---|---|---|
|
IF THEN ELSE |
|
|
|
Difference in two dates (use day, week, month, year, hour, minute, second, millisecond as unit) |
|
|
|
Returns |
|
Returns |
|
Converts the specified string to lowercase |
|
E.g. the text RED Apple will be converted to |
Functions can also be combined, e.g. to convert values to lowercase and look for the values that include the word "green" in them, the formula would like as follows:
contains(lowerCase($Contact), "green")
For a list of existing date functions refer here.
For a list of existing string functions refer here.
For a list of existing conversion functions refer here.