Version
3. Listeners
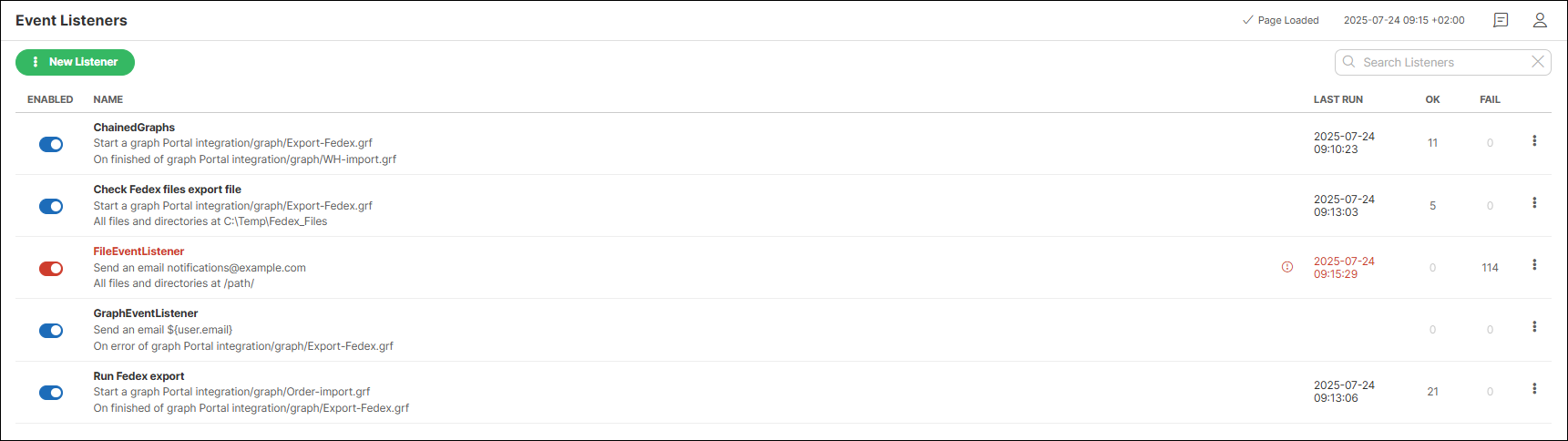
Listeners can be seen as 'hooks'. They wait for a specific event and take a used-defined action if the event occurs. Created listeners are shown in the Event Listeners list.
Figure 19. List of listeners
The list of listeners provides the following information and options:
| Column name | Description |
|---|---|
Enabled |
Indicates whether the listener is enabled or disabled. Clicking the icon enables/disables the listener. |
Name |
Shows the name of the listener, task type and event the listener is waiting for. |
Last run |
Shows the date and time of the last run. |
OK |
Shows the number of successful runs. |
FAIL |
Shows the number of failed runs. |
⋮ |
Click the kebab menu to open a submenu with the following options:
|
Clicking on a listener opens a pane on the right side, where the Overview tab displays additional information such as the listener description[1] (if provided), last run time, the creation[2] and last update date along with the associated user[3], and other listener details.
You can set up alerts and notifications for failed schedules on the Alerts and Notifications tab.
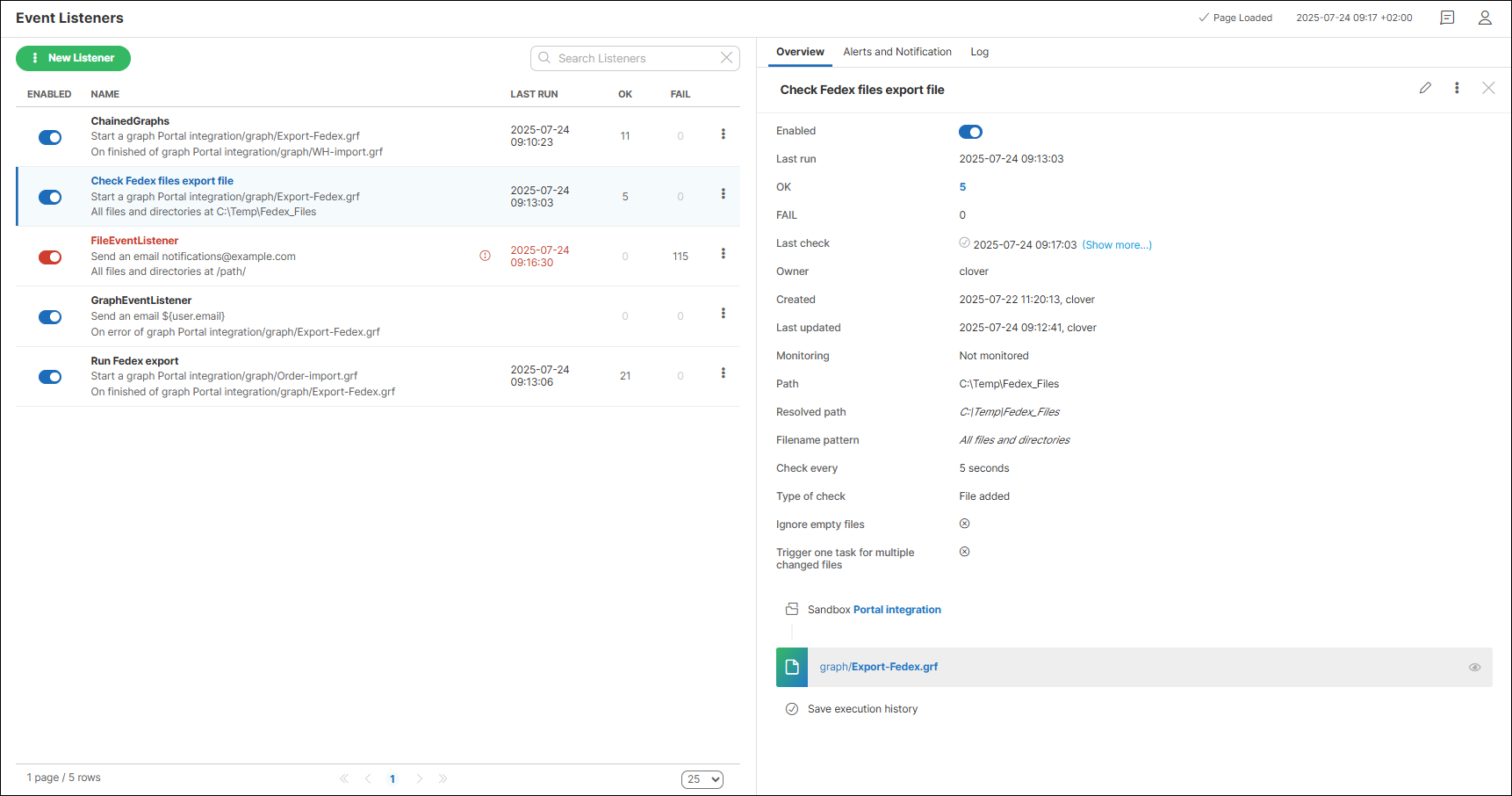
Figure 20. Listener detail
Some listeners also display the Log tab, where you can review a log file of past events and their results.
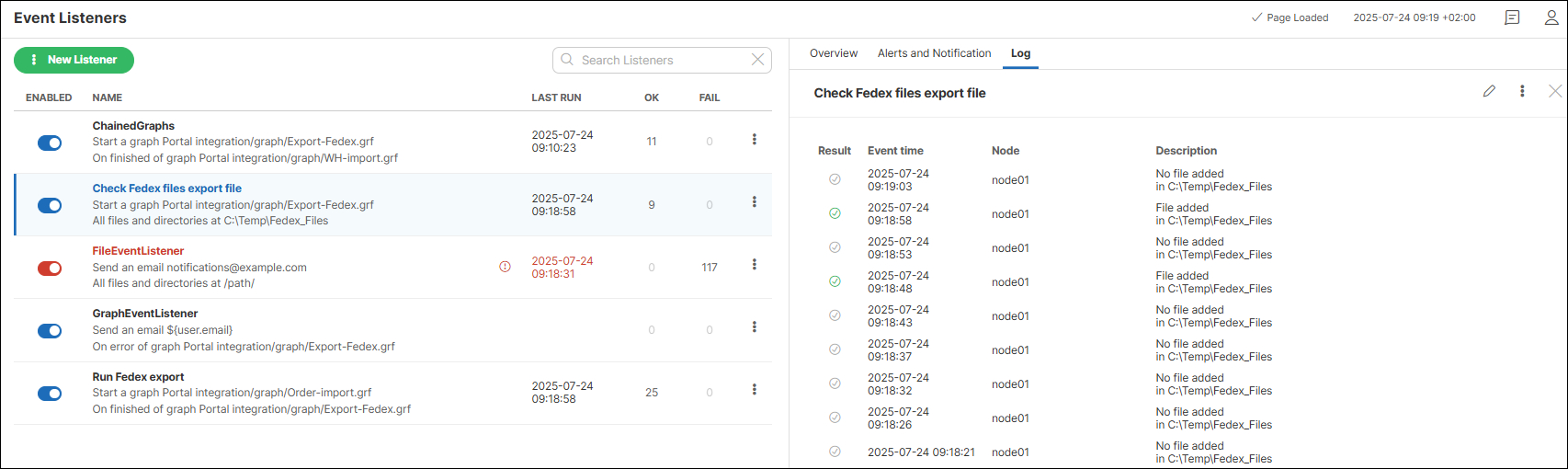
Figure 21. Log tab
When creating a listener, you can pick from several listener types, each with its own specific configuration. Below is the list of available listener types:
Each listener can be configured to trigger one the following tasks:
Graph Event Listeners
Graph Event Listeners allow you to define a task that the Server will execute as a reaction to the success, failure or other event of a specific job (a transformation graph).
Each listener is bound to a specific graph and is evaluated no matter whether the graph was executed manually, scheduled, or via an API call, etc.
You can use listeners to chain multiple jobs (creating a success listener that starts the next job in a row). However, we recommend using Jobflows to automate complex processes because of its better development and monitoring capabilities.
Graph Event Listeners are similar to Jobflow Event Listeners (Jobflow Event Listeners) – for CloverDX Server both are simply 'jobs'.
In the cluster, the event and the associated task are executed on the same node the job was executed on, by default. If the graph is distributed, the task will be executed on the master worker node. However, you can override where the task will be executed by explicitly specifying a Node IDs in the task definition.
Graph events
Each event carries properties of a graph, which is the source of the event.
If there is an event listener specified, the task may use these properties.
For example the next graphs in a chain may use "EVENT_FILE_NAME" placeholder which was activated by the first graph in the chain.
Graph properties, which are set specifically for each graph run (e.g. RUN_ID), are overridden by the last graph.
Types of graph events
Graph started
The Graph started event is created, when a graph starts its execution (i.e. it gets to the RUNNING status). If the graph was enqueued, then this event is triggered when the graph is pulled from the queue and started.
Graph phase finished
The Graph phase finished event is created, every time a graph phase is finished and all its nodes are finished with status FINISHED_OK.
Graph finished
The Graph finished event is created, when all phases and nodes of a graph are finished with FINISHED_OK status.
Graph error
The Graph error event is created, when a graph cannot be executed for some reason, or when any node of graph fails.
Graph aborted
The Graph aborted event is created, when a graph is explicitly aborted.
Graph timeout
The Graph timeout event is created, when a graph runs longer than a specified interval. If the graph was enqueued, then the time it spent waiting in the queue is not taken into its run time - only the time it actually spent running is used (i.e. when it’s in RUNNING state).
You have to specify the Job timeout interval for each listener of a graph timeout event. You can specify the interval in seconds, minutes or hours.
Graph unknown status
The Graph unknown status event is created when the Server, during the startup, detects run records with undefined status in the Execution History. Undefined status means, that the Server has been killed during the graph run. The Server automatically changes the state of the graph to Not Available and sends a graph unknown status event.
Please note that this works just for executions, which have a persistent record in the Execution History. It is possible to execute a transformation without a persistent record in the Execution History, typically for better performance of fast running transformations (e.g. using Data Services).
Listener
User may create a listener for a specific event type and graph (or all graphs in sandbox). The listener is actually a connection between a graph event and a task, where the graph event specifies when and the task specifies what to do.
Event handling consists of the following course of actions:
-
the event is created
-
listeners for this event are notified
-
each listener performs the related task
Tasks
Task types are described in Tasks.
In the cluster environment, all tasks have an additional attribute Node IDs to process the task. If there is no node ID specified, the task may be processed on any cluster node. In most cases, it will be processed on the same node where the event was triggered. If there are some nodeIDs specified, the task will be processed on the first node in the list which is connected in cluster and ready.
Use cases
Possible use cases are:
Execute graphs in chain
For example, we have to execute graph B, only if another graph A finished without any error.
So there is a relation between these graphs.
We can achieve this behavior by creating a graph event listener.
We create a listener for graph finished OK event of graph A and choose an execute graph task type with graph B specified for execution.
If we create another listener for graph B with the execute graph task with graph C specified, it will work as a chain of graphs.
| Avoid specifying the same graph in both the "Graph to check" and "Triggered task" fields, as this could result in an infinite loop. |
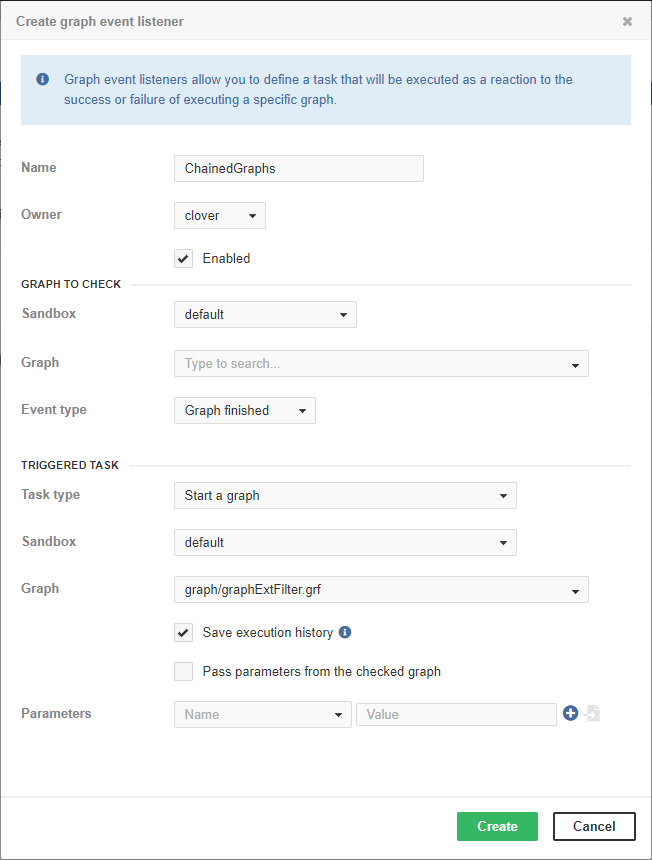
Figure 22. Demonstration of a setup where if one graph finishes successfully, another graph is automatically started.
Email notification about graph failure
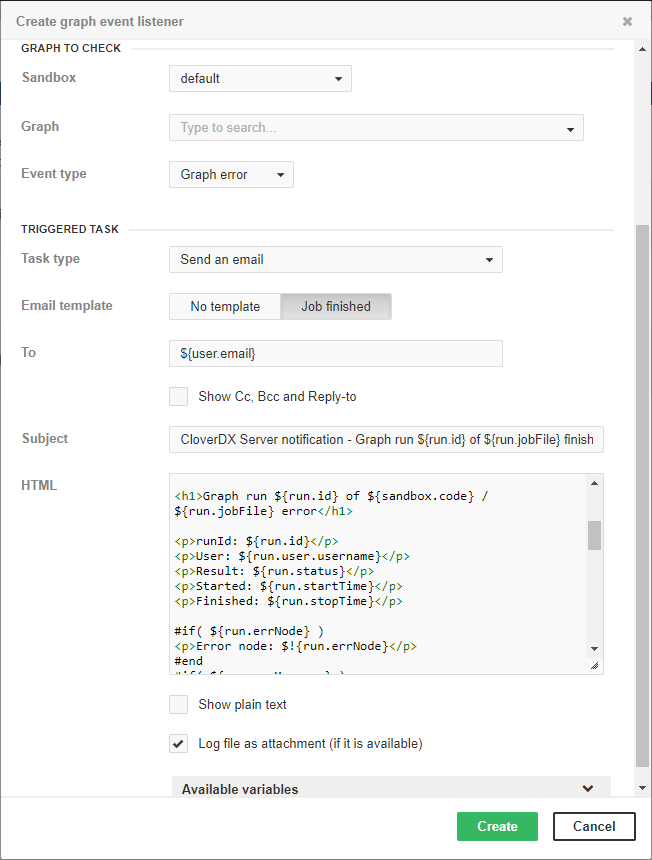
Figure 23. Web GUI - email notification about graph failure
Email notification about graph success
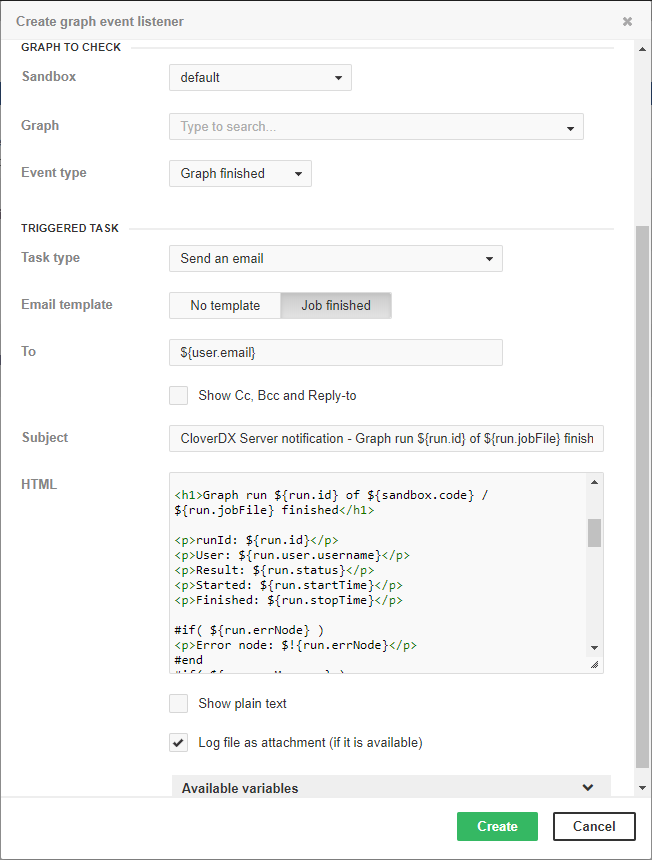
Figure 24. Web GUI - email notification about graph success
Backup of data processed by graph
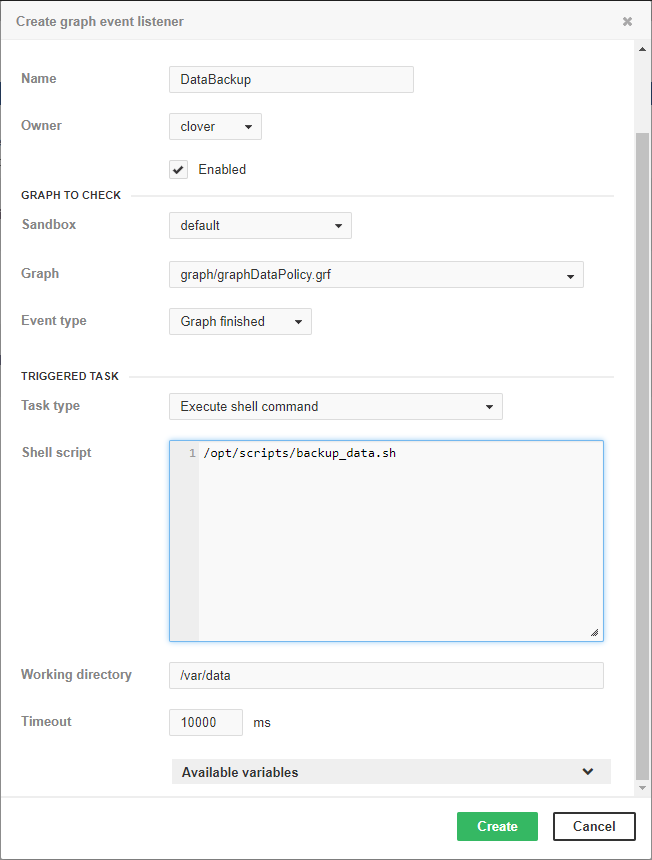
Figure 25. Web GUI - backup of data processed by graph
Jobflow Event Listeners
Jobflow Event Listeners allow you to define a task that the Server will execute as a reaction to the success or failure of executing a specific job (a jobflow).
Each listener is bound to a specific jobflow and is evaluated every time the jobflow is executed (no matter whether manually, through another jobflow, via a schedule, API call, etc.).
Jobflow Event Listeners work very similarly to Graph Event Listeners in many ways, since Graphs and Jobflows are both 'jobs' from the point of view of the CloverDX Server.
In the cluster, the event and the associated task are executed on the same node the job was executed on. If the jobflow is distributed, the task will be executed on the master worker node. However, you can override the default setting by explicitly specifying a Node ID in the task definition.
Jobflow events
Each event carries properties of the event source job.
If there is an event listener specified, a task may use these properties.
For example, the next job in the chain may use "EVENT_FILE_NAME" placeholder which activated the first job in the chain.
Job properties, which are set specifically for each run (e.g. RUN_ID), are overridden by the last job.
Types of jobflow events
Jobflow started
A Jobflow started event is created, when a jobflow starts its execution (i.e. it gets to the RUNNING status). If the jobflow was enqueued, then this event is triggered when the jobflow is pulled from the queue and started.
Jobflow phase finished
The Jobflow phase finished event is created every time a jobflow phase is finished and all its nodes are finished with the FINISHED_OK status.
Jobflow finished
The Jobflow finished event is created, when all phases and nodes of a jobflow are finished with the FINISHED_OK status.
Jobflow error
The Jobflow error event is created, when a jobflow cannot be executed for some reason, or when any node of the jobflow fails.
Jobflow aborted
The Jobflow aborted event is created, when a jobflow is explicitly aborted.
Jobflow timeout
The Jobflow timeout event is created, when a jobflow runs longer than a specified interval. If the jobflow was enqueued, then the time it spent waiting in the queue is not taken into its run time - only the time it actually spent running is used (i.e. when it’s in RUNNING state).
You have to specify the Job timeout interval for each listener of the jobflow timeout event. You can specify this interval in seconds, minutes or hours.
Jobflow unknown status
The Jobflow unknown status event is created, when the Server, during the startup, detects run records with undefined status in the Execution History. Undefined status means, that the Server has been killed during the jobflow run. The server automatically changes the state of the jobflow to Not Available and sends the jobflow status unknown event.
Please note, that this works just for executions which have a persistent record in the Execution History. It is possible to execute a transformation without a persistent record in the Execution History, typically for better performance of fast running transformations (e.g. using Data Services).
Listener
The user may create a listener for the specified event type and jobflow (or all jobflows in sandbox). The listener is actually a connection between the jobflow event and task, where the jobflow event specifies when and the task specifies what to do.
Event handling consists of the following course of actions:
-
event is created
-
listeners for this event are notified
-
each listener performs the related task
Tasks
A task specifies an operation which should be performed as a reaction to a triggered event.
Task types are described in Tasks.
Note: You can use a task of any type for a jobflow event listener. The description of task types is divided into two sections just to show the most evident use cases.
JMS Message Listeners
JMS Message Listeners allow you to listen for incoming JMS messages. You can specify the source of the messages (JMS Topic or JMS Queue) and a task that will be executed for incoming messages.
JMS messaging requires a JMS API (javax.jms-api-2.0.jar) and third-party libraries. All these libraries must be available on classpath of an application server and classpath of Worker. Libraries must be added before starting the CloverDX Server.
|
JMS Message Listeners on Worker
JMS Message Listener always runs on Server Core, but you can use it to execute jobs on Worker.
In such a case, make sure that the required |
In cluster, you can either explicitly specify which node will listen to JMS or not. If unspecified, all nodes will register as listeners. In the case of JMS Topic, all nodes will receive all messages and trigger the tasks (multiple instances) or, in the case of JMS Queue, a random node will consume the message and run the task (just one instance).
JMS Message Listener modes
JMS Message Listener supports two modes which influence its life cycle.
You can choose between these modes by enabling/disabling the Trigger new task for every message option:
| Mode | Description |
|---|---|
Non-batch (default) |
The listener connects to the JMS source (queue/topic) and responds to each incoming message by triggering the selected task (e.g. graph or jobflow). The connection to the source is not interrupted during the process. |
Batch |
The listener connects to the JMS source (queue/topic) and waits for a message. Once the message is received, it stays in the queue, the listener disconnects from the source and triggers the selected task (e.g. graph or jobflow). Once the task is finished, the listener reconnects to the source and waits for another message. This way, the triggered task can use JMSReader component to connect to the same source and consume large number of messages, increasing performance. The listener is disconnected from the source for the duration of the triggered task, up to the task.jms.callback.timeout duration. |
Attributes of JMS Message Listener
Below is the list of attributes which can be set up for JMS Message Listeners:
| Attribute | Description |
|---|---|
Initialize by |
This attribute is useful only in a cluster environment. It is a node ID or list of node IDs where the listener should be initialized. If it is not set, the listener is initialized on all nodes in the cluster. In the cluster environment, each JMS event listener has Initialize by attribute which may be used to specify the cluster node which will consume messages from the queue/topic. There are the following possibilities:
In a standalone environment, the Initialize by attribute is ignored. |
JNDI Access |
|
Initial context |
Default or custom |
Initial context factory class |
A full class name of the The specified class must be on the application-server classpath. It is usually included in one library with a JMS API implementation for each specific JMS provider. |
Broker URL |
A URL of a JMS message broker |
Listen To |
|
Connection factory |
A JNDI name of a connection factory. It depends on the name of the registered jndi resource, e.g. |
Username |
A username for a connection to a JMS message broker. For some providers it is enough to define username in the JNDI resource definition and this attribute can be left empty. |
Password |
A password for a connection to JMS message broker. For some providers it is enough to define password in the JNDI resource definition and this attribute can be left empty. |
Queue/Topic |
A JNDI name of a message queue/topic. It depends on the name of the registered jndi resource, e.g. |
Durable subscriber |
If false, the message consumer is connected to the broker as 'non-durable', so it receives only messages which are sent while the connection is active. Other messages are lost. If the attribute is true, the consumer is subscribed as 'durable' so it receives even messages which are sent while the connection is inactive. The broker stores such messages until they can be delivered or until the expiration is reached. This switch is useful only for Topics destinations, because Queue destinations always store messages until they can be delivered or the expiration is reached. Please note that consumer is inactive e.g. during server restart and during short moment when the user updates the "JMS message listener" and it must be re-initialized. So during these intervals, the message in the Topic may get lost if the consumer does not have the durable subscription. If the subscription is durable, client must have ClientId specified.
This attribute can be set in different ways in dependence on JMS provider.
E.g.
for ActiveMQ, it is set as a URL parameter |
Subscriber name |
Available only when Durable subscriber is |
Message selector |
This query string can be used as a specification of conditions for filtering incoming messages. Syntax is well described on Java EE API web site. It has different behavior depending on the type of consumer (queue/topic): Queue: Messages that are filtered out remain in the queue. Topic: Messages filtered out by a Topic subscriber’s message selector will never be delivered to the subscriber. From the subscriber’s perspective, they do not exist. |
Message Processing |
|
Number of consumers |
How many consumers will be initialized on every cluster node registered as a listener. |
Groovy code |
A Groovy code may be used for additional message processing and/or for refusing a message. Both features are described below. |
Optional Groovy code
Groovy code may be used for additional message processing or for refusing a message.
-
Additional message processing: Groovy code may modify/add/remove values stored in the containers "properties" and "data".
-
Refuse/acknowledge the message: If the Groovy code returns
Boolean.FALSE, the message is refused. Otherwise, the message is acknowledged. A refused message may be redelivered, however the JMS broker should configure a limit for redelivering messages. If the Groovy code throws an exception, it’s considered a coding error and the JMS message is NOT refused because of it. So, if the message refusal is to be directed by some exception, it must be handled in Groovy.
| Type | Key | Description |
|---|---|---|
javax.jms.Message |
msg |
Instance of a JMS message |
java.util.Properties |
properties |
See below for details. It contains values (String or converted to String) read from a message and it is passed to the task which may then use them. For example, the execute graph task passes these parameters to the executed graph. |
java.util.Map<String, Object> |
data |
See below for details. Contains values (Object, Stream, etc.) read or proxied from the message instance and it is passed to the task which may then use them. For example, the execute graph task passes it to the executed graph as dictionary entries. |
jakarta.servlet.ServletContext |
servletContext |
An instance of ServletContext. |
com.cloveretl.server.api.ServerFacade |
serverFacade |
An instance of serverFacade usable for calling CloverDX Server core features. |
java.lang.String |
sessionToken |
SessionToken needed for calling serverFacade methods |
Message data available for further processing
A JMS message is processed and the data it contains is stored into two data structures: Properties and Data.
| Key | Description |
|---|---|
JMS_PROP_[property key] |
For each message property, one entry is created where "key" is made of the |
JMS_MAP_[map entry key] |
If the message is an instance of MapMessage, for each map entry, one entry is created where "key" is made of the |
JMS_TEXT |
If the message is an instance of TextMessage, this property contains content of the message. |
JMS_MSG_CLASS |
A class name of a message implementation. |
JMS_MSG_CORRELATIONID |
Correlation ID is either a provider-specific message ID or an application-specific String value. |
JMS_MSG_DESTINATION |
The JMSDestination header field contains the destination to which the message was sent. |
JMS_MSG_MESSAGEID |
JMSMessageID is a String value that should function as a unique key for identifying messages in a historical repository. The exact scope of uniqueness is provider-defined. It should at least cover all messages for a specific installation of a provider, where an installation is some connected set of message routers. |
JMS_MSG_REPLYTO |
A destination to which a reply to this message should be sent. |
JMS_MSG_TYPE |
A message type identifier supplied by the client when the message was sent. |
JMS_MSG_DELIVERYMODE |
The DeliveryMode value specified for this message. |
JMS_MSG_EXPIRATION |
The time the message expires, which is the sum of the time-to-live value specified by the client and the GMT at the time of the send. |
JMS_MSG_PRIORITY |
The JMS API defines ten levels of priority value (0 = lowest, 9 = highest). In addition, clients should consider priorities 0-4 as gradations of normal priority and priorities 5-9 as gradations of expedited priority. |
JMS_MSG_REDELIVERED |
|
JMS_MSG_TIMESTAMP |
The time a message was handed off to a provider to be sent. It is not the time the message was actually transmitted, because the actual send may occur later due to transactions or other client-side queueing of messages. |
Note that all values in the “Properties” structure are stored as a String type – however they are numbers or text.
For backwards compatibility, all listed properties can also be accessed using lower-case keys; however, it is a deprecated approach.
| Key | Description |
|---|---|
JMS_DATA_MSG |
An instance of javax.jms.Message. |
JMS_DATA_STREAM |
An instance of java.io.InputStream. Accessible only for TextMessage, BytesMessage, StreamMessage, ObjectMessage (only if a payload object is an instance of String). Strings are encoded in UTF-8. |
JMS_DATA_TEXT |
An instance of String. Only for TextMessage and ObjectMessage, where a payload object is an instance of String. |
JMS_DATA_OBJECT |
An instance of java.lang.Object - message payload. Only for ObjectMessage. |
The Data container is passed to a task that can use it, depending on its implementation. For example, the task execute graph passes it to the executed graph as dictionary entries.
In a cluster environment, you can explicitly specify node IDs, which can execute the task. However, if the data payload is not serializable and the receiving and executing node differ, an error will be thrown as the cluster cannot pass the data to the executing node.
Inside a graph or a jobflow, data passed as dictionary entries can be used in some component attributes.
For example, the File URL attribute would look like: "dict:JMS_DATA_STREAM:discrete" for reading the data directly from the incoming JMS message using a proxy stream.
If the graph is executed on Worker, the dictionary entries must be serializable; otherwise, they cannot be passed to the graph.
For backwards compatibility, all listed dictionary entries can also be accessed using lower-case keys; however, it is a deprecated approach.
Using JMS Message Listener with RabbitMQ
Connecting to RabbitMQ queues is possible using client library: https://github.com/rabbitmq/rabbitmq-jms-client
The JNDI resource for RabbitMQ connection factory requires additional configuration to work seamlessly with JMS Message Listener. Example JNDI resource definitions for connection factory and a queue, for Tomcat:
<Resource name="jms/MyConnectionFactory"
type="javax.jms.ConnectionFactory"
factory="com.rabbitmq.jms.admin.RMQObjectFactory"
username="guest"
password="guest"
virtualHost="/"
host="hostname_of_broker_goes_here"
port="5672"
onMessageTimeoutMs="3600000"
keepTextMessageType="true"
terminationTimeout="0"
channelsQos="1"
/>
<Resource name="jms/MyQueue"
type="javax.jms.Queue"
factory="com.rabbitmq.jms.admin.RMQObjectFactory"
destinationName="whatever"
amqp="true"
amqpQueueName="MyQueueName"
amqpExchangeName=""
amqpRoutingKey="MyQueueName"
/>Explanation of additional configuration properties:
-
onMessageTimeoutMs - Lets the JMS listener wait until triggered graph finishes before processing next message. This configuration is needed for proper function of the listener.
-
channelsQos - Prevents processing of prefetched messages after disabling the listener. This configuration is needed for proper function of batch mode.
-
terminationTimeout - Prevents delay between finish of triggered task and processing of next message. This configuration is needed for proper function of batch mode.
-
keepTextMessageType - Allows sending of TextMessage instead of BytesMessage type. This configuration is needed only if you use Send JMS Message task.
To find official descriptions of the configuration properties and more information, see RabbitMQ documentation.
|
JMS is a complex topic that goes beyond the scope of this document. For more detailed information about JMS, refer to the Oracle website: https://docs.oracle.com/javaee/7/tutorial/jms-concepts.htm#BNCDQ |
Kafka Message Listeners
Overview
Kafka Message Listeners allow you to listen for incoming events in specified Kafka topic(s) and trigger tasks in reaction to these incoming Kafka events.
This can be used namely to automatically process these Kafka events using a job as a triggered task.
The listener offers two ways of specifying which Kafka connection to use. Either by using an existing connection configuration file (.cfg), or by using an existing job file (graph, jobflow) with a Kafka connection defined.
In the first case, an additional parameters file can be selected to resolve any potential parameters used in the connection.
Users have to ensure no other consumer is subscribed to the same configuration as the listener. Or else the listener may fail. |
|
Kafka message listener subscribes to a topic and waits for appearance of new events with a timeout defined by configuration property clover.event.kafkaPollInterval. The poll either ends when new events appear - the Kafka connection is closed and the specified task is triggered, or after this interval passes - the Kafka connection is re-created. This interval can be raised or lowered if the default value is undesirable. |
|
If the offset for the specified group is not found during listener initialization, the new offset is automatically committed to the end of the stream. This is important to allow the triggered graph to actually read the new incoming events detected by the listener. |
Kafka Message Listener attributes
Below is the list of attributes which can be set up for Kafka Message Listeners:
| Attribute | Description |
|---|---|
Name |
The listener name. |
Owner |
Clover user to use for the listener. |
Enabled |
The state of listener. |
Kafka Connection |
|
Load connection from |
Possible values are:
|
Sandbox |
The sandbox which contains the Kafka configuration file or job file. |
Connection file |
Connection configuration file (.cfg) which defines the Kafka cluster connection. Available only if configuration file (.cfg) is selected. |
Parameters file |
An additional parameters file used to resolve any potential parameters used in the connection. The default workspace.prm parameter file in the selected sandbox is always used for parameter resolution. Using this option, you can also select an additional parameter file. Optional, and available only if configuration file (.cfg) is selected. |
Job file |
Job file (graph, jobflow) which contains a Kafka cluster connection. Available only if job file (.grf, .jbf) is selected. |
Connection |
A Kafka connection to use. Available only if job file (.grf, .jbf) is selected. |
Kafka Topic(s) |
|
Topic specified by |
Possible values are:
|
Topic name(s) |
Kafka topic, which will be used to listen for events. Possible values are: a single topic name or a semicolon-separated list of topic names. Available only if Topic specified by - name is selected. |
Topic pattern |
Kafka topic name pattern (regular expression). Matched topics will be used to listen for events. Available only if Topic specified by - regular expression is selected. |
Group name |
A Kafka consumer group to use for the listener. |
Parameters passed from the listener to the task
The listener passes a set of predefined parameters to the triggered task. Usage of these parameters allows you to write more generic jobs to process the Kafka events.
For example, you can use parameter EVENT_KAFKA_TOPICS in Kafka components to work with the same topics as the listener.
| Parameter | Description |
|---|---|
EVENT_USERNAME |
The name of the user who caused the event. |
EVENT_USER_ID |
A numeric ID of the user who caused the event. |
EVENT_KAFKA_LISTENER_ID |
An ID of the listener which triggered the event. |
EVENT_KAFKA_TOPICS |
Kafka topic name(s) defined in the listener which triggered the event. |
EVENT_KAFKA_TOPICS_PATTERN |
Kafka topic name pattern defined in the listener which triggered the event. |
EVENT_KAFKA_GROUP |
Kafka consumer group defined in the listener which triggered the event. |
Permissions
To be able to use Kafka message listeners, the user need to have the proper group permissions assigned. These permissions are:
-
List Kafka message listeners limited/unlimited - for listing and viewing existing listeners, either those belonging to a user-owned sandbox, or all listeners.
-
Create Kafka message listener - for creating new listeners.
-
Edit Kafka message listener - for editing existing listeners.
-
Delete Kafka message listener - for deleting existing listeners.
Universal Event Listeners
Since 2.10
Universal Event Listeners allow you to write a piece of Groovy code that controls when an event is triggered, subsequently executing a predefined task.
The Groovy code is periodically executed and when it returns TRUE, the task is executed.
| Attribute | Description |
|---|---|
Node IDs to handle the event |
In a cluster environment, each universal event listener has a Node IDs attribute which may be used to specify which cluster node performs the Groovy code. There are following possibilities:
In a standalone environment, the Node IDs attribute is ignored. |
Interval of check in seconds |
Periodicity of Groovy code execution. |
Groovy code |
Groovy code that evaluates either to |
Groovy code
A piece of Groovy is repeatedly executed and evaluated; based on the result, the event is either triggered and the task executed or no action is taken.
For example, you can continually check for essential data sources before starting a graph. Or, you can do complex checks of a running graph and, for example, decide to kill it if necessary. You can even call the CloverDX Server Core functions using the ServerFacade interface, see Javadoc accessible from CloverDX Server via http(s)://host:port/clover/javadoc/index.html.
Evaluation criteria
If the Groovy code returns Boolean.TRUE, the event is triggered and the associated task is executed.
Otherwise, nothing happens.
If the Groovy code throws an exception, it is considered a coding error and the event is NOT triggered. Thus, exceptions should be properly handled in the Groovy code.
| Type | Key | Description |
|---|---|---|
java.util.Properties |
properties |
An empty container which may be filled with String-String key-value pairs in your Groovy code. It is passed to the task which may use them somehow. For example, the task execute graph passes these parameters to the executed graph. |
java.util.Map<String, Object> |
data |
An empty container which may be filled with String-Object key-value pairs in your Groovy code. It is passed to the task which may use them somehow according to its implementation - e.g. the task execute graph passes it to the executed graph as dictionary entries. Note that it is not serializable, thus if the task is relying on it, it can be processed properly only on the same cluster node. |
jakarta.servlet.ServletContext |
servletContext |
An instance of ServletContext in which CloverDX Server is running. |
com.cloveretl.server.api.ServerFacade |
serverFacade |
An instance of serverFacade usable for calling CloverDX Server core features. |
java.lang.String |
sessionToken |
A sessionToken needed for calling methods on the serverFacade. |
File Event Listeners (remote and local)
Local file-system changes: Since 1.3
Remote file-system changes: Since 4.2
File Event Listeners allow you to monitor changes on a specific local file system path or remote URL – for example, new files appearing in a folder – and react to such an event with a predefined task.
You can specify an exact file name or use a wildcard/regexp. Alternatively, leave the Filename pattern field empty to include all files and directories. Then set a checking interval in seconds and define a task to process the event.
There is a global minimum check interval that you can change if necessary in the configuration (the clover.event.fileCheckMinInterval property). See List of configuration properties.

Figure 26. Web GUI - creating a File Event listener
| Parameter | Description |
|---|---|
EVENT_USERNAME |
The name of the user who caused the event. |
EVENT_USER_ID |
A numeric ID of the user who caused the event. |
EVENT_FILE_NAME |
The name of the file (without the path or URL) that triggered the event. Present only when Trigger one task for multiple changed files is disabled. |
EVENT_FILE_PATH |
A resolved (without placeholders) path to the observed directory on the local filesystem. Valid only for a local file listener. |
EVENT_FILE_PATTERN |
A filename pattern. |
EVENT_FILE_EVENT_TYPE |
The type of the file event.
Possible values: |
EVENT_FILE_LISTENER_ID |
An ID of the listener which triggered the event. |
EVENT_FILE_URLS |
Full URLs to access the files, e.g.
in the File URL attribute of components.
If Trigger one task for multiple changed files is enabled and there are multiple URLs, they are separated by a separator specified by CloverDX Engine property |
EVENT_FILE_AUTH_USERNAME |
A username/ID to the remote location. |
EVENT_FILE_AUTH_USERNAME_URL_ENCODED |
The same as |
EVENT_FILE_AUTH_PASSWORD |
A password/key to the remote location. It is encrypted by the master password. |
EVENT_FILE_AUTH_PASSWORD_URL_ENCODED |
The same as |
Cluster environment
In a cluster environment, each file event listener has a Node IDs attribute which may be used to specify which cluster node will perform the checks on its local file system. There are following possibilities:
-
No failover: Just one node ID specified - Only the specified node observes the local/remote filesystem; however, the node status must be "ready". When the node isn’t ready, the file system isn’t checked at all.
To create a file event listener with no failover, select One of selected nodes in Initialize by and select one node from the table below.
-
Failover with node concurrency:: No node ID specified (empty input) - All cluster nodes with the status "ready" concurrently check the local/remote filesystem according to file event listener attributes settings. In this mode, when the listener is configured to observe the local filesystem, each cluster node observes its own local file system. So it’s useful only when the observed path is properly shared among the cluster nodes. It may behave unpredictably otherwise. On the other hand, when the listener is configured to observe the remote filesystem, listeners running on different cluster nodes may connect to the same remote resource. The nodes use a locking mechanism when accessing the local or remote filesystem, so no conflict between listeners running concurrently on different nodes can occur.
To create a file event listener with node concurrency, select Any node in Initialize by.
-
Failover with node reservation: More node IDs specified (separated by comma) - Just one of the specified nodes checks its filesystem. If the node fails for any reason (or its status isn’t "ready"), any other "ready" node from the list continues with checking. Please note, that when file event listener is re-initialized on another cluster node, it compares the last directory content detected by the failed node with the current directory content.
To create a file event listener with node reservation, select One of selected nodes in Initialize by and select more nodes.
In a standalone environment, the Node IDs attribute is ignored.
Supported filesystems and protocols
Local filesystem
The user may specify a path to the directory which the listener shall observe. The listener doesn’t read the directory content recursively. The directory must exist.
If the listener can run concurrently on more nodes, the directory must be shared among all these nodes and the directory must exist on all these nodes. In a cluster environment, the directory must exist on each cluster node where the listener may run.
It is recommended to use placeholders to unify the configuration on all nodes.
The recommended placeholders are: CloverDX Server config property ${sandboxes.home} and JVM system property ${java.io.tmpdir}.
It is possible to use any JVM system property or Environment variable.
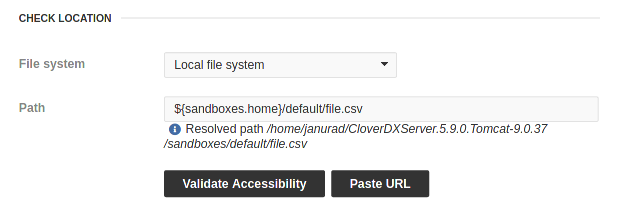
Figure 27. File available on local file system
Remote filesystem
The user may specify a URL to the directory which the listener shall observe. The supported protocols are: FTP, SFTP, Amazon S3, Azure Blob Storage, SMB version 1, and SMB versions 2 and 3. Different protocols may use different authentication methods: none, username+password and keystore. The listener doesn’t read the directory content recursively. The directory must exist.
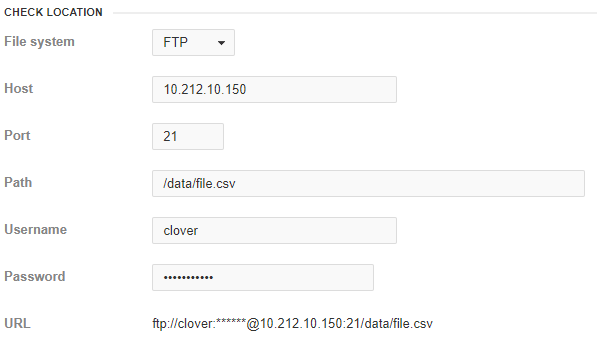
Figure 28. File available on remote location
Currently the subset of the protocols allowed by file-operations is supported:
-
FTP - File Transfer Protocol (no authentication or username + password authentication) URL example:
ftp://host:23/observed/path/
-
SFTP (SSH/FTP) - SSH File Transfer Protocol (username + password authentication) URL example:
sftp://host:23/observed/path/
It is recommended to use placeholders to unify the path configuration on all nodes. The recommended placeholders are: CloverDX Server config property
${sandboxes.home}, JVM system property${user.home}. It is possible to use any JVM system property or Environment variable. -
S3 - Amazon S3 Storage (AWS Access Key ID + Secret Access Key authentication) URL example:
s3://s3.amazonaws.com/bucketname/path/
Please specify the AWS Access Key ID as a username and Secret Access Key as a password.
-
Azure Blob Storage (Storage Shared Key) URL example:
az-blob://accountname.blob.core.windows.net/container/path/
Please specify the storage Account Name and Account Key.
-
Azure Blob Storage (Client Secret) URL example:
az-blob://accountname.blob.core.windows.net/container/path/
Please specify the storage Account Name and Tenant ID, Client ID and Client Secret.
-
Microsoft SMB/CIFS Protocol (domain + username + password authentication) URL example:
smb://domain%3Buser:password@server/path/
-
Microsoft SMBv2/v3 Protocol (domain + username + password authentication) URL example:
smb2://domain%3Buser:password@server/path/
Due to the upgrade of the SMBJ library in CloverDX version 6.2, anonymous access using SMB protocol version 2 or 3 will no longer work unless your Samba server is configured to stop requiring message signing. If turning off message signing is not an option, you can create a user without a password to use in the URL as a workaround. See below for example URLs:smb2://domain%3Buser@server/path/smb2://domain%3Buser:@server/path/
|
Observed file
The local observed file is specified by a directory path and file name pattern.
The remote observed file is specified by a URL, credentials and file name pattern.
The user may specify just one exact file name or file name pattern for observing more matching files in specified directory. If there are more changed files matching the pattern, separated event is triggered for each of these files.
There are several ways how to specify file name pattern of observed file(s):
All files and directories
To observe all files and directories, leave the Filename pattern field empty.
Exact match
You specify the exact name of the observed file.
Wildcards
You can use wildcards common in most operating systems (*, ?, etc.)
-
*- Matches zero or more instances of any character -
?- Matches one instance of any character -
[…]- Matches any of characters enclosed by the brackets -
\- Escape character
Examples
-
*.csv- Matches all CSV files -
input_*.csv- Matches i.e. input_001.csv, input_9.csv -
input_???.csv- Matches i.e. input_001.csv, but does not match input_9.csv
Regular expression
Examples
-
(.*?)\.(jpg|jpeg|png|gif)$- Matches image files
Notes
-
It is strongly recommended to use absolute paths with placeholders. It is possible to use a relative path, but the working directory depends on an application server.
-
Use forward slashes as file separators, even on MS Windows. Backslashes might be evaluated as escape sequences.
File events
For each listener you have to specify event type, which you are interested in.
Please note that since CloverETL 4.2, the grouping mode may be enabled for the file listener, so all file changes detected by a single check produce just one 'grouped' file event. Otherwise each single file produces its own event.
There are four types of file events:
File added
Event of this type occurs, when the observed file is created or copied from another location between two checks. Please keep in mind that event of this type occurs immediately when a new file is detected, regardless if it is complete or not. Thus task which may need a complete file is executed when the file is still incomplete. Recommended approach is to save the file to a different location and when it is complete, rename it or move it to an observed location where CloverDX Server may detect it. File moving/renaming should be an atomic operation.
An event of this type does not occur when the file has been updated (change of timestamp or size) between two checks. Appearance means that the file didn’t exist during the previous check and it exists now, during the current check.
File removed
Event of this type occurs, when observed file is deleted or moved to another location between two checks.
File size changed
Event of this type occurs when the size of the observed file has changed between two checks. Event of this type is never produced when the file is created or removed. The file must exist during both checks.
File timestamp changed
Event of this type occurs, when timestamp of the observed file has changed between two checks. Event of this type is never produced when the file is created or removed. The file must exist during both checks.
Check Interval, Task and Use Cases
-
The user may specify the minimum time interval between two checks. Use the Check every field to specify the interval in seconds.
-
Each listener defines a task which will be processed as a reaction to the file event. All task types and theirs attributes are described in the Scheduling and Graph Event Listeners sections.
-
Graph Execution when a file with input data is accessible.
-
Graph Execution when a file with input data is updated.
-
Graph Execution when a file with generated data is removed and must be recreated.
-
How to use source of event during task processing
A file(s) which caused the event (considered as a source of the event) may be used during task processing. CloverDX graph/jobflow components with the File URL attribute (e.g.
reader or writer components) may directly use an event source by parameter placeholder: ${EVENT_FILE_URLS}.
For another parameters, see Executed by Task Graph Execution by File Event Listener.
Note that previous versions used lower-case placeholders. Since version 3.3, placeholders are upper-case, however lower-case still work for backward compatibility.
For graph execution task this works only if the graph is not pooled.
Thus keep in pool interval must be set to 0 (default value).
Delayed triggering for incomplete files
It is possible to delay task execution for incomplete files. This is useful in cases when the condition to execute the listener’s task has been met, but there is still some work that needs to be done on the file, e.g. the whole file needs to be uploaded.
Ignore empty files
If the process creating the file creates an empty file, then switch to different task for several minutes or even hours and finally writes the content, tick Ignore empty files checkbox. The task will be triggered only if a non-empty file appears.
Trigger task when file has not changed for n checks
If the file size slowly rises until the file is complete, tick the checkbox Trigger task when file has not changed. Then specify the number of additional file size checks that are to be performed on the file. The listener’s task will not be triggered until the checks are performed and the file’s size stays the same between these checks.
Combination
If you use Ignore empty files and Trigger task when file has not changed for n checks together, the first one filters out empty files and the latter one the files that are being changed. The task will be triggered only on files that are not empty and that have not changed for the specified number of checks.
Howtos
Create a file event listener listening to changes on local file system |
Create a file event listener listening to changes on local file system
This guide shows a way to create a new listener checking appearance of a file (new_invoices.txt) on a local file system (/mnt/sdb2/). The appearance will trigger a graph (graph/checkInvoices.grf) from the InvoicesProcessing sandbox.
In Event Listeners, click New Listener and select File Listener.
Enter the Name of the listener, e.g. Invoices.
Enter the Path to the directory where files will appear: /mnt/sdb2.
You can check that CloverDX can access this directory (the directory exists and permissions are set up properly) with the Validate Accessibility button.
If the observed directory becomes inaccessible, CloverDX Server can send you an email. To do so, tick Send email on check failure and enter recipient(s).
The event should be triggered on file appearance - set Type of check to File added.
Enter the file name new_invoices.txt to Filename pattern.
Alternatively, leave the field empty to observe all files and directories.
If the file is created empty, but the content is written after some time, tick Ignore empty files. Doing so, the task will be executed after the file contains some data.
If it takes a long time to copy the whole file to the observed position, the CloverDX Server can perform several check to ensure that the file to process is not to be changed. Tick Trigger task when file has not changed for and enter the number of checks. If you tick Ignore empty files, this checks will be performed after the file is not empty.
Choose Sandbox with the graph (InvoicesProcessing) and the graph (graph/checkInvoices.grf).
To save the changes, click on the Create button.
Use SSH public key authentication with SFTP listener
Key-based authentication can be achieved using the openssh.config.file configuration property.
This sets a path to a SSH client configuration file, in which you can set the individual SSH client options.
For the purpose of this example, namely the IdentityFile option.
Create the SSH client configuration file, e.g.:
Host sftp.example.com
Port 9022
User example
IdentityFile /home/example/.ssh/id_rsaUse the private key file, which will be used to authenticate on the SFTP server.
Configure the Server property to point to this configuration file location, e.g.:
openssh.config.file=/home/example/.ssh/configIf you are using a passphrase to protect your private key file add the Server property. Note the username and hostname in the property name.
openssh.key.passphrase.myuser@sftp.example.com=changeitCreate the File Event Listener as usual, select File system SFTP (SSH/FTP), fill in fields Host, Port, Username and Path. Connection can now be validated using Validate Accessibility button.
You need to enter values for hostname, port or username in the listener form, even if they are specified in the SSH client configuration file. |
Configure the rest of the listener as needed.
Observe file from one cluster node
Create the listener in the same way as on the Server.
Switch Initialize by to One of selected nodes.
Add the particular node(s) from Available nodes to Selected nodes.
Quickly enable or disable file event listener
In , there is a table with event listeners. In this table, click the icon in the Enabled column.
Pasting URL
The whole URL including user name and password can be pasted at once. Click Paste URL and paste the string.
If the name or password in URL contain special characters, e.g. +, the special characters should be encoded: ftp://anonymous:test%2B@example.com/dir/file.txt
Note: use encoding accepted by the java.net.URLDecoder.decode() function.
Task Failure Listeners
Since 4.4
Task Failure Listeners allow you to detect and react to failures in your server when a task you set up in a listener fails to execute, e.g. a File Listener is set up to detect changes on an FTP server, but it fails to connect to the FTP server.
Use the Trigger limit attribute, to set up the maximum number of times the Task Failure Listener triggers a reaction to failure.
Task Failure Listeners do not detect failures of the task itself, e.g. a File Listener is set up to detect changes on an FTP server and send an email if the change is detected. If the File Listener fails to send the email for some reason, the Task Failure Listener won’t detect it.
The same tasks to be executed are available as with all the other listeners, the difference is that when creating a new Task Failure Listener the pre-selected task is Sending an email if the email service is configured in Configuration.

Figure 29. Web GUI - creating a Task Failure listener
Task Choice
There are three options to choose from: Listening to any task failure, listening to failures from a group (such as File Event Listeners) or listening to a failure of a chosen listener.
Selecting an option from the Listen to type menu restricts the Listen to combobox to event sources of the chosen category. If there are no event sources in the category, the Failure Listener can still be created, it will react to failures of tasks that will be created in that category.
When selecting an event source, you can type into the text field to filter the dropdown menu. After selecting an event source, some information is presented about the listener.
When sending an email, you can use the 'task failed' template by selecting it from the E-mail template dropdown menu.
Task Failed E-mail Template
The default email template may be modified using placeholders described in Placeholders and parameters in Parameters usable in task failure email template. Furthermore, some additional parameters can be used if the failed listener is a File Event Listener, see File Event Listener specific parameters usable in task failure email template.
| Parameter | Description |
|---|---|
TASK_LISTENER_ID |
The ID of the failed listener. |
TASK_LISTENER_NAME |
The name of the failed listener. |
TASK_LISTENER_TYPE |
The type of the failed listener. |
TASK_LISTENER_TYPE_TEXT |
The full name of the failed listener’s type. |
TASK_LISTENER_OWNER_USERNAME |
The owner of the failed listener. |
| Parameter | Description |
|---|---|
FILE_EVENT_LISTENER_FILE_PATH |
The path to the observed directory. |
FILE_EVENT_LISTENER_FILE_REMOTE_URL |
The full remote URL of the observed directory. |
FILE_EVENT_LISTENER_FILE_NAME_PATTERN |
The filename pattern of the files the listener observes. |
FILE_EVENT_LISTENER_FILE_CHECK_TYPE |
The type of check the listener performs. |
FILE_EVENT_LISTENER_FILE_MATCH_TYPE |
The listener’s filename match type. |
FILE_EVENT_LISTENER_FILE_NODE |
The Node IDs of nodes the listener can be initialized by. |
Alerts and notifications
The Alerts and Notification tab allows setting the condition when an Event Listener is marked as failing. You can also set up email notifications for the failures here and set up monitoring in the Operations Dashboard. See Alerts and Notification for more details.
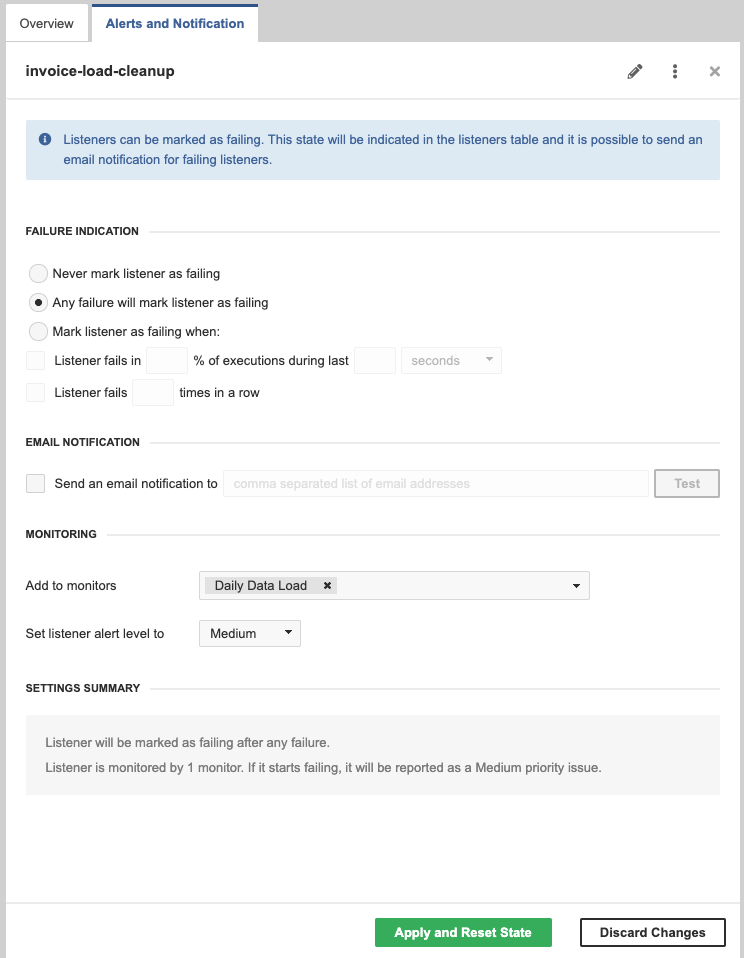
Figure 30. Event Listeners - Alerts and Notification