Version
53. Sandboxes in Cluster
There are three sandbox types in total - shared sandboxes, and partitioned and local sandboxes (introduced in 3.0) which are vital for parallel data processing.
Shared Sandbox
This type of sandbox must be used for all data which is supposed to be accessible on all Cluster nodes. This includes all graphs, jobflows, metadata, connections, classes and input/output data for graphs which should support high availability (HA). All shared sandboxes reside in the directory, which must be properly shared among all Cluster nodes. You can use a suitable sharing/replicating tool according to the operating system and filesystem.
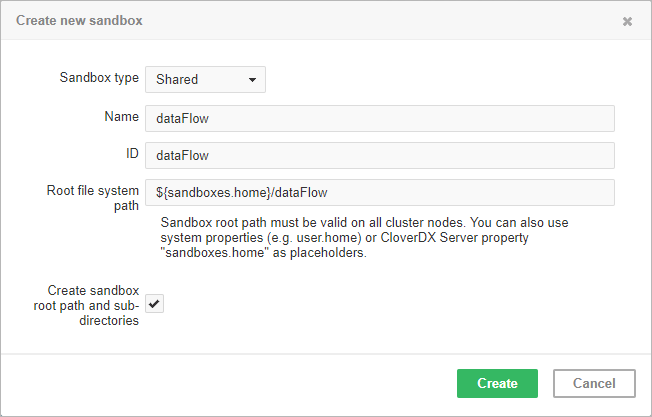
Figure 245. Dialog form for creating a new shared sandbox
As you can see in the screenshot above, you can specify the root path on the filesystem and you can use placeholders or absolute path.
Placeholders available are environment variables, system properties or CloverDX Server configuration property intended for this use: sandboxes.home.
Default path is set as [user.data.home]/CloverDX/sandboxes/[sandboxID] where the sandboxID is an ID specified by the user.
The user.data.home placeholder refers to the home directory of the user running the JVM process (/home subdirectory on Unix-like OS); it is determined as the first writable directory selected from the following values:
-
USERPROFILEenvironment variable on Windows OS -
user.homesystem property (user home directory) -
user.dirsystem property (JVM process working directory) -
java.io.tmpdirsystem property (JVM process temporary directory)
Note that the path must be valid on all Cluster nodes; not just nodes currently connected to the Cluster, but also on nodes that may be connected later. Thus when the placeholders are resolved on a node, the path must exist on the node and it must be readable/writable for the JVM process.
Local Sandbox
This sandbox type is intended for data, which is accessible only by certain Cluster nodes. It may include massive input/output files. The purpose being, that any Cluster node may access content of this type of sandbox, but only one has local (fast) access and this node must be up and running to provide data. The graph may use resources from multiple sandboxes which are physically stored on different nodes since Cluster nodes can create network streams transparently as if the resources were a local file. For details, see Using a Sandbox Resource as a Component Data Source.
Do not use a local sandbox for common project data (graphs, metadata, connections, lookups, properties files, etc.), as it can cause odd behavior. Use shared sandboxes instead.
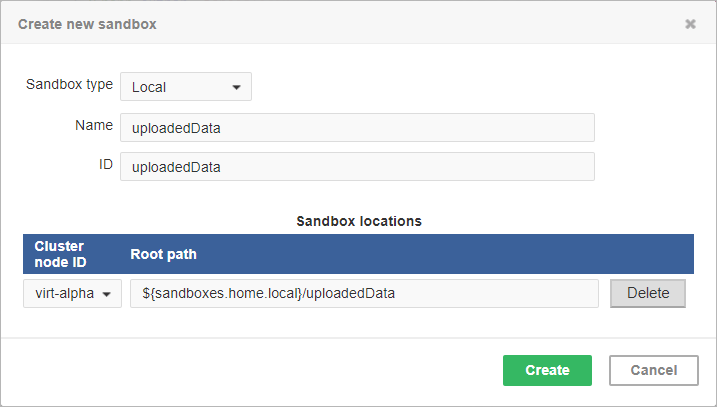
Figure 246. Dialog form for creating a new local sandbox
The sandbox location path is pre-filled with the sandboxes.home.local placeholder which, by default, points to [user.data.home]/CloverDX/sandboxes-local.
The placeholder can be configured as any other CloverDX configuration property.
Partitioned Sandbox
This type of sandbox is an abstract wrapper for physical locations existing typically on different Cluster nodes. However, there may be multiple locations on the same node. A partitioned sandbox has two purposes related to parallel data processing:
-
node allocation specification
Locations of a partitioned sandbox define the workers which will run the graph or its parts. Each physical location causes a single worker to run without the need to store any data on its location. In other words, it tells the CloverDX Server: to execute this part of the graph in parallel on these nodes.
-
storage for part of the data
During parallel data processing, each physical location contains only part of the data. Typically, input data is split in more input files, so each file is put into a different location and each worker processes its own file.
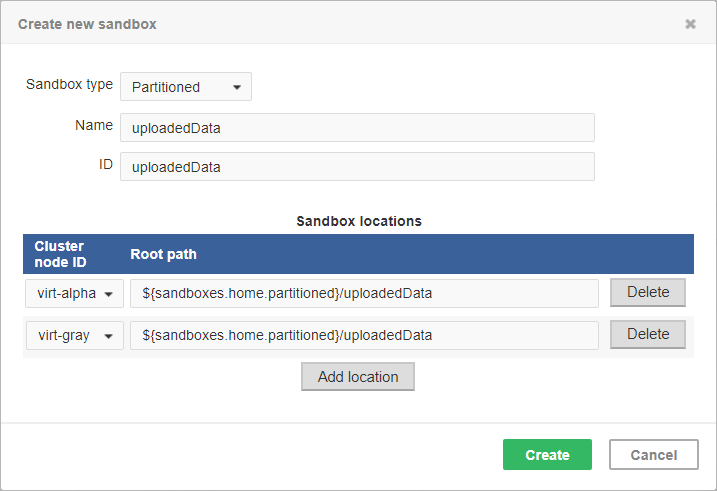
Figure 247. Dialog form for creating a new partitioned sandbox
As you can see on the screenshot above, for a partitioned sandbox, you can specify one or more physical locations on different Cluster nodes.
The sandbox location path is pre-filled with the sandboxes.home.partitioned placeholder which, by default, points to [user.data.home]/CloverDX/sandboxes-paritioned.
The sandboxes.home.partitioned config property may be configured as any other CloverDX Server configuration property.
Note that the directory must be readable/writable for the user running JVM process.
Do not use a partitioned sandbox for common project data (graphs, metadata, connections, lookups, properties files, etc.), as it can cause odd behavior. Use shared sandboxes instead.
Using a Sandbox Resource as a Component Data Source
A sandbox resource, whether it is a shared, local or partitioned sandbox (or an ordinary sandbox on a standalone Server), is specified in the graph under the fileURL attributes as a so called sandbox URL:
sandbox://data/path/to/file/file.dat
where data is the code for the sandbox and path/to/file/file.dat is the path to the resource from the sandbox root.
The URL is evaluated by CloverDX Server during job execution and a component (reader or writer) obtains the opened stream from the Server.
This may be a stream to a local file or to some other remote resource.
Thus, a job does not have to run on the node which has local access to the resource.
There may be more sandbox resources used in the job and each of them may be on a different node.
The sandbox URL has a specific use for parallel data processing. When the sandbox URL with the resource in a partitioned sandbox is used, that part of the graph/phase runs in parallel, according to the node allocation specified by the list of partitioned sandbox locations. Thus, each worker has its own local sandbox resource. CloverDX Server evaluates the sandbox URL on each worker and provides an open stream to a local resource to the component.
The sandbox URL may be used on a standalone Server as well. It is an excellent choice when graph references some resources from different sandboxes. It may be metadata, lookup definition or input/output data. A referenced sandbox must be accessible for the user who executes the graph.
Remote Edges
Data transfer between graphs running on different nodes is performed by a special type of edge - remote edge. The edge utilizes buffers for sending data in fixed-sized chunks. Each chunk has a unique number; therefore, in the case of an I/O error, the last chunk sent can be re-requested.
You can set up values for various remote edge parameters via configuration properties. For list of properties, their meaning and default values, see Optional Remote Edge Properties.
The following figure shows how nodes in a Cluster communicate and transfer data - the client (a graph running on Node 2) issues an HTTP request to Node 1 where a servlet accepts the request and checks the status of the source buffer. The source buffer is the buffer filled by the component writing to the left side of the remote edge. If the buffer is full, its content is transmitted to the Node 2, otherwise the servlet waits for a configurable time interval for the buffer to become full. If the interval has elapsed without data being ready for download, the servlet finishes the request and Node 2 will re-issue the request at later time. Once the data chunk is downloaded, it is made available via the target buffer for the component reading from the right side of the remote edge. When the target buffer is emptied by the reading component, Node 2 issues new HTTP request to fetch the next data chunk.
This communication protocol and its implementation have consequences for the memory consumption of remote edges. A single remote edge will consume 3 x chunk size (1.5MB by default) of memory on the node that is the source side of the edge and 1 x chunk size (512KB by default) on the node that is the target of the edge. A smaller chunk size will save memory; however, more HTTP requests will be needed to transfer the data and the network latency will lower the throughput. Large data chunks will improve the edge throughput at the cost of higher memory consumption.
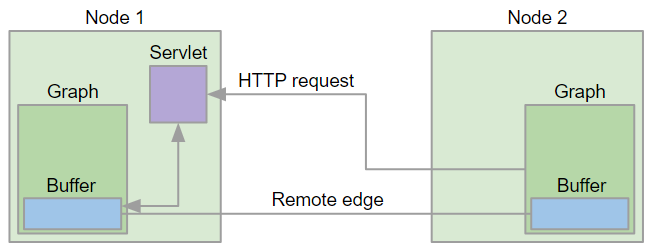
Figure 248. Remote Edge Implementation