1. Getting started
- How Wrangler works (video)
- Quick tutorial (video)
- Source: Choosing data for your job
- Combining multiple data sources
- Job anatomy: Understanding steps and repeatability
- What to consider before adding a column
- Column data types
- Formulas and calculations
- Modify values based on a condition
- Working with strings (text)
- Working with decimals (including currency)
- Working with dates
- Errors in your data
- No data or some missing?
- No value: Working with null and empty values
- Replacing empty value with a default value
- Filtering data
- Getting results from your job
- Target: Configuring job output
- Mapping your data to specific target
Welcome to Wrangler!
To get yourself comfortable with CloverDX Wrangler, we recommend you take the following path to learn the Wrangler basics so that you can later explore additional functionality on your own:
-
Start with a quick introduction video How Wrangler works (2 minutes).
-
Watch this 15 minute Quick tutorial that will guide you through a sample task.
-
Explore the rest of this Getting Started section (use the menu on the left) to learn the key principles of the Wrangler.
-
Start your own project!
-
Use the steps reference part of this documentation to understand each transformation step in detail.
How Wrangler works (video)
This video provides a brief overview of what Wrangler is and what you can do with it.
Quick tutorial (video)
We highly recommend you follow this quick tutorial before you start exploring on your own.
The video will walk you through building your first Wrangler job and explain the core principles in detail. You can then read additional details in the rest of this guide.
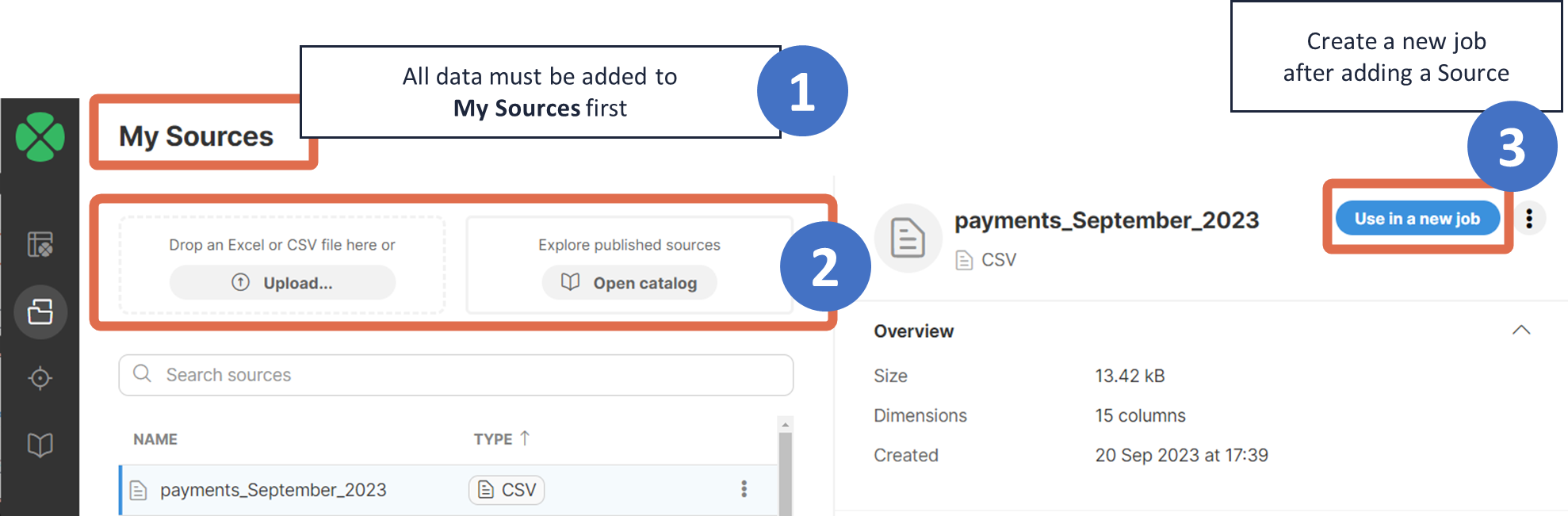
Source: Choosing data for your job
CloverDX Wrangler uses concepts of data sources and data targets to define where the data comes from and where it is written at the end of the transformation. To learn more about targets and their configuration, see target file configuration.
A data source is the location from where your data is loaded. All sources that you can work with are listed in the Data Catalog and in My Sources section.
Data Catalog provides an overview of the sources published by your organization - this is where you can find your source systems like CRM, data warehouse, and anything else your organization published.
My Sources section allows you to see all sources that you’ve created and configured in the past.
Data sources can be created in multiple ways:
-
from a CSV or Excel file uploaded to Wrangler in My Sources or when editing the job’s configuration.
-
from an existing data source connector in the Data Catalog. Connectors in the Data Catalog are defined and managed by your organization’s IT team. To add a new source based on a connector, select it in the Data Catalog and click on Add to My Sources, or to use it in a new job right away, click on Use in a new job.
See data sources for more information.
Combining multiple data sources
Each job must have one main source and it can also optionally include any number of additional sources which are used in lookups.
To add ("join") additional lookup sources to your job, follow these steps:
-
Open the My Sources screen and add the additional source(s) either from the Data Catalog or by uploading CSV or Excel files with lookup data.
-
Go back to your job and add the Lookup step to the transformation as appropriate. In the lookup configuration pick the data source you created in the previous step.
If you need to add multiple lookups each with a different lookup data source, repeat the above process as many times as necessary.
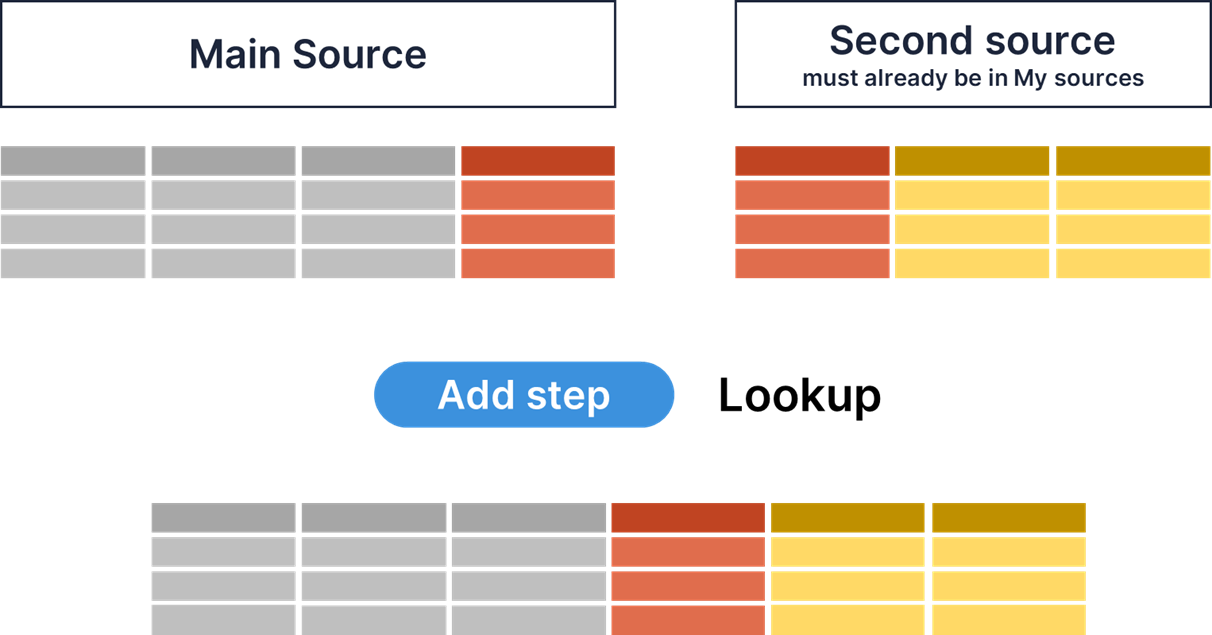
Lookup configuration
-
Lookup data source
-
Pick the lookup (second) source you want to add to your data set (your data set will be joined with the lookup data).
-
It needs to be in My sources first, otherwise, it won’t be visible in the dropdown.
-
-
Data column
-
Typically, the "ID" or "key" column in the main source (CustomerID, InvoiceNumber, etc).
-
-
Lookup column
-
The corresponding "ID" or "key column in the lookup source (the other CustomerID, InvoiceNumber, etc).
-
-
Columns to add from lookup
-
Choose which column(s) you want to load from the second source. You will be able to transform them further in subsequent steps in your job if needed.
-
Lookup hints
Things to bear in mind when working with lookups:
-
Values added from the Lookup step will always be added as new columns. You cannot overwrite existing columns with a Lookup step (you can do that in subsequent steps).
-
When there are values in your data set for which no matches have been found in the lookup data, the output columns will be left empty (
null). If you want to populate all such values with a static (default) value, you can use the Replace empty values step. -
Lookups are case-sensitive, and the data used as keys in the lookup must match exactly with the data in your dataset in order to be matched.
-
When the data source used in an existing Lookup step is deleted and uploaded again, the step will need to be edited and the lookup source file selected again.
-
The source file should not include duplicate keys. For example, the table below includes currencies and conversion rates, where "EUR" appears twice. If this data is used in a lookup to pull the rates, only the first rate (1.07) for EUR will be used.
| The data preview in Wrangler is limited to 1000 rows. If the lookup file or source file includes more than 1000 rows, it might happen that you will not see any matched data from the lookups when editing the job. Refer to the following section for more information on how to proceed. |
For more information about the Lookup step, see here.
Job anatomy: Understanding steps and repeatability
Instead of manipulating data directly and potentially doing something you might regret in the future, Wrangler records the steps you’re taking and then plays them back on the source data when the job is executed. Source data is never modified in any way.
You can always go back to change, remove, disable, or insert steps in your job to revert or modify the actions you’ve taken in the past.
Example: We initially deleted 'Profit margin' but later realized we might be needing it.
We can remove Step 2 (Delete column 'Profit margin') to bring the column back to our dataset as if we never deleted it in the first place. All subsequent actions will still be applied.
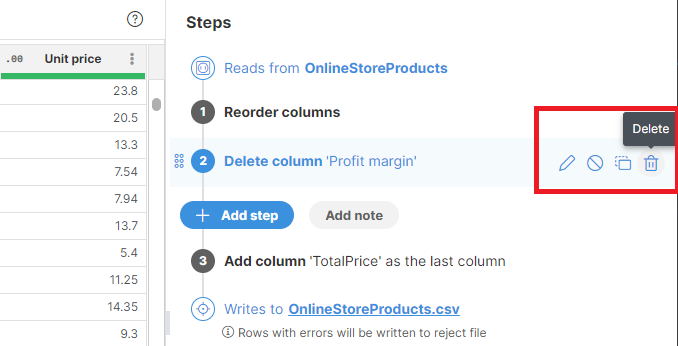
Tip: Steps are your safeguard against making mistakes. Any decision you’ve made in the past can be reverted or modified.
Disable a step if you don’t want to remove it just yet. Disabled steps won’t have any effect on the data and will stay in the job until you delete them.
See Using Steps sidebar for more information.
Moving between steps
The preview always shows the data corresponding to the currently highlighted step. You can freely move around the steps to see what the data looks like at each point in the sequence. To see the final output, click on the last step.
Example:
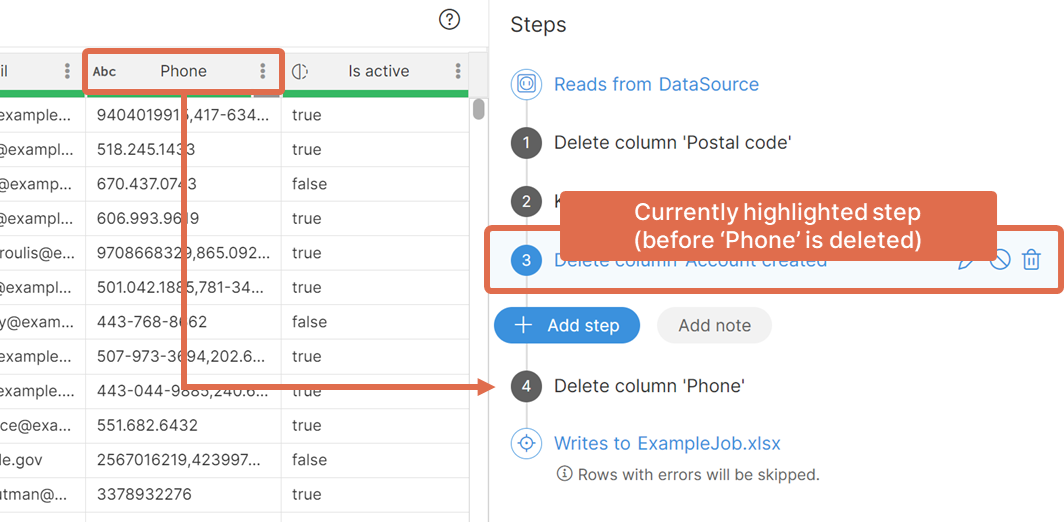
Phone is still visible here because step 3 is selected. Clicking on the last step will show a preview without the Phone column since it is removed in step 4.
See Using Steps sidebar for more information.
What to consider before adding a column
Before using the Add column step, note that there are steps that add a new column automatically:
-
The Lookup step will automatically add one or more columns with data from the lookup depending on the step configuration.
-
The Calculate formula step has an option to create a new column.
In both scenarios, you don’t need to explicitly add a new column beforehand - both the Lookup and Calculate formula steps add columns for you.
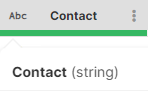
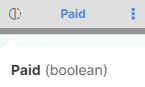
Column data types
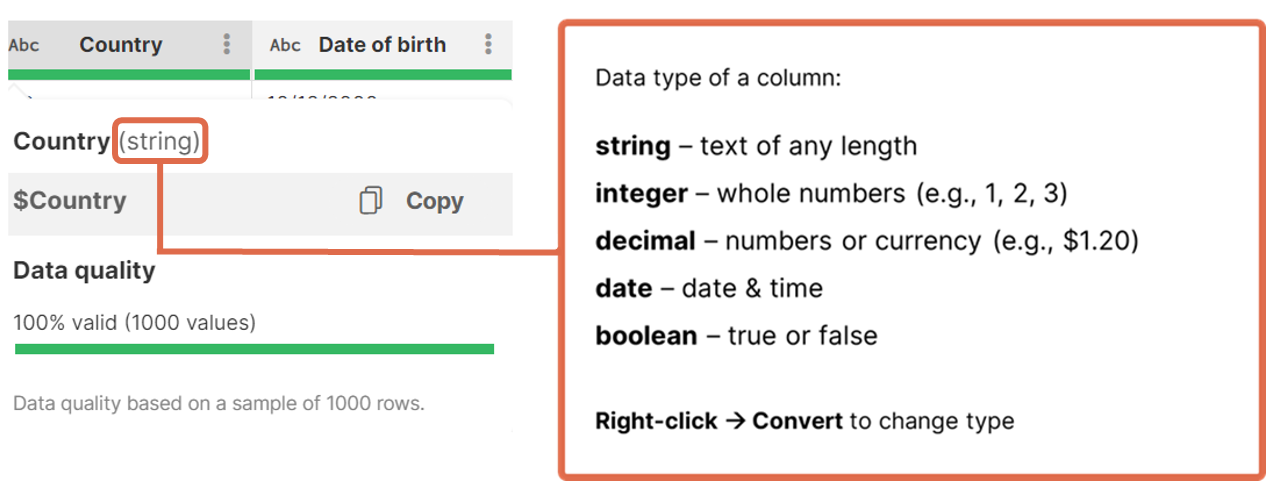
All columns in CloverDX Wrangler have a type which defines what kind of data can be stored in the column - whether it is a number, date or text. Types are either automatically detected (for example when reading from a CSV file) or they are provided by the data source (when reading from a data source connector from the Data Catalog).
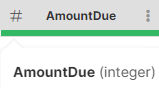
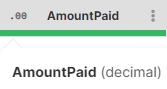
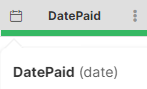
The data type for each column is indicated by an icon in the column header with additional information available in the tooltip shown when hovering over a column header. The following table shows how different types are visualized in the data preview.
| Data type | Example column | Example usage |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
For more information about data types, refer here.
Since having the correct data type is essential when working with your data, it is important to review the loaded data. If the type is not the type you would expect, you can convert column to a different type by using one of the conversion steps:
Formulas and calculations
Formulas can be entered in the following steps:
Formulas are also used in step and group conditions. For more information, see Step and group conditions.

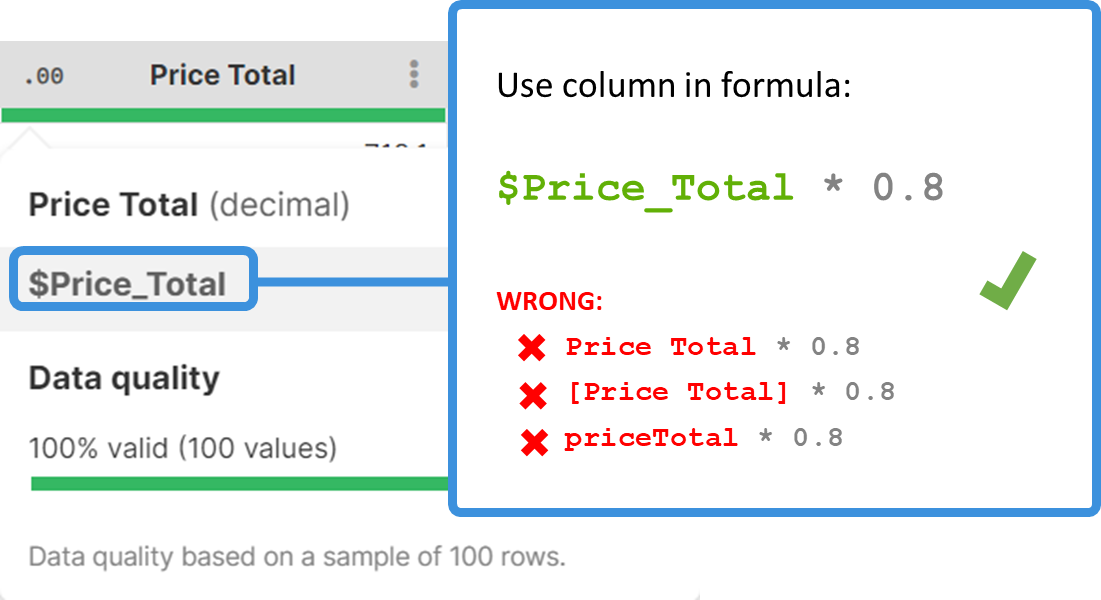
In your formulas, you will need to specify the column(s) that you want to work with. A column is referenced by its technical column name - a name that is automatically created by Wrangler by stripping various special characters from the column label (e.g., a column with the label Invoice amount (USD) will have the technical name $Invoice_amount_USD). Technical column names always include the $ sign to make it easy to distinguish from other names that can appear in formulas.
To find and easily copy the technical column name, hover over a column header.
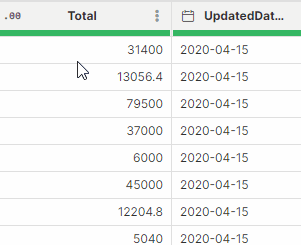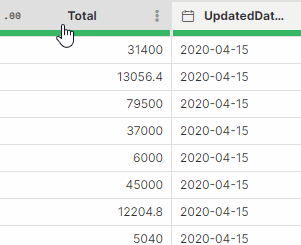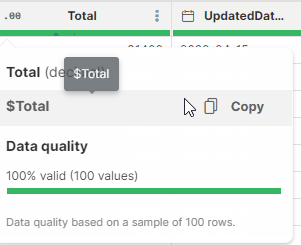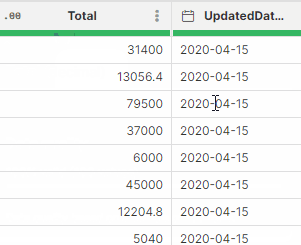
Technical column names are case-sensitive and need to be entered in the exact form as displayed. If you mistype a technical column name, you will get an error like this:
Error: Field '$invoice_amount_USD' does not exist in record 'invoices_csv'
You can also use the autocomplete functionality in Formula Editor, which automatically displays a list of all existing technical column names after you type the $ character. Alternatively, you can display the list of all technical column names and all available functions by using the Ctrl + Space shortcut.
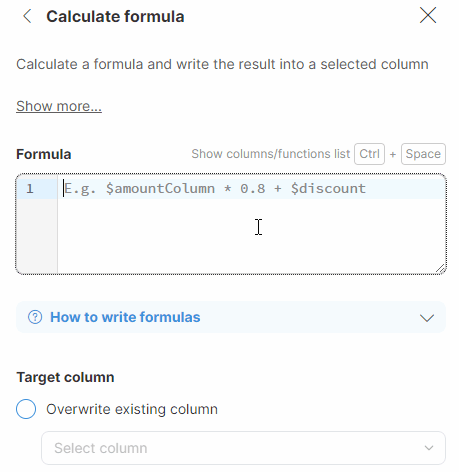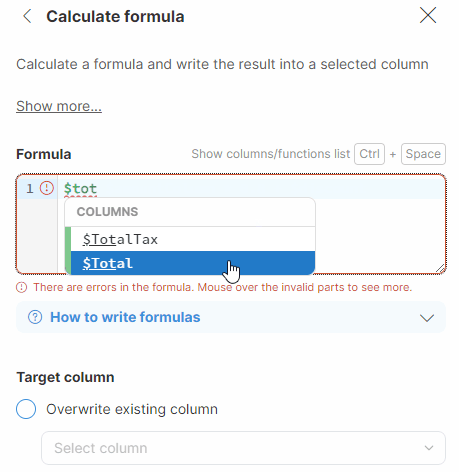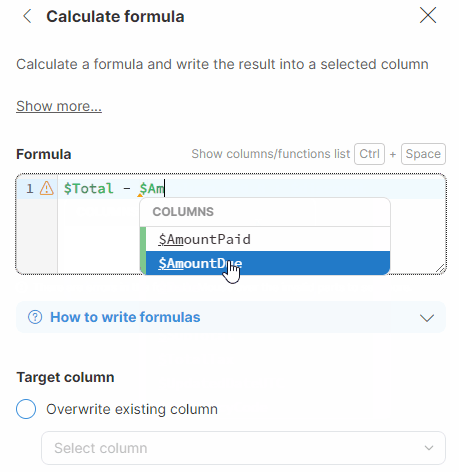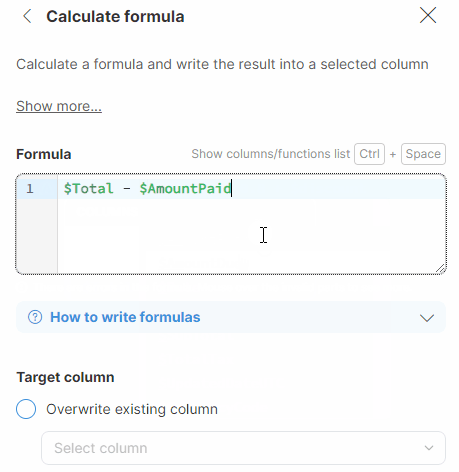
Comparing values
The operators below can be used to compare values; however, note that that you can only compare values with the same data types.
| Operator | Description |
|---|---|
|
Equal to (double =) for all data types |
|
Not equal to |
|
Greater than |
|
Greater or equal |
|
Less than |
|
Less or equal |
Important information to bear in mind:
-
When working with decimals, you need to specify all the decimal places in the unformatted form in your formula. Decimal values can also only include decimal points; commas as decimal separators are not supported. See Working with decimals (including currency) for more information.
-
When working with dates, make sure to enter them in the
YYYY-MM-dd format(orYYYY-MM-dd HH:mm:sswhen using full date and time). See Working with dates for more information. -
When working with strings, the values need to be enclosed in double or single quotes. See Working with strings (text) for more information.
-
When working with empty values, see No value: Working with null and empty values for more information.
| Example | Explanation |
|---|---|
|
Returns |
|
Returns |
|
Returns |
|
Returns |
|
Often the best option. |
|
Returns |
|
Returns |
Calculations and functions
| Operator | Description | Example formula | Result |
|---|---|---|---|
|
Add numbers |
|
|
|
Concatenate strings |
|
|
|
Subtract numbers |
|
|
|
Multiply numbers |
|
|
|
Divide integers |
|
500 if |
|
Divide decimals |
|
500.5 if |
|
Modulo (remainder after division) |
|
|
When working with columns that include numbers (integers or decimals), you can use mathematical operators.
Note: With the exception of the + operator, these operators cannot be used for any other data types than integers or decimals. If you, e.g., attempt to use the - operator when working with date columns, you will get the following error:
Error: Operator '-' is not defined for types: 'date' and 'date'
The + operator can be used as a concatenation function to join values from multiple columns when working with string values (or a combination of string and other data types values; however, in such a case a use of other functions to set the desired format might be needed: more information on this can be found in the Functions section). You can also optionally insert a space or any other characters in between the values.
Example: You want to join invoice numbers and status values and want to enter the & symbol in between, preceded and followed by a space:
$InvoiceNumber + ' & ' + $Status
For more complex cases, you can use one of our built-in functions. The autocomplete feature in Formula Editor suggests relevant functions as you type. Alternatively, you can use the CTRL + Space shortcut to display the list of available column names (marked in green, starting with the $ sign) and functions (marked in purple). When inserting a function, placeholders for its parameters are automatically included, providing guidance for formula construction. Substitute these placeholders with the appropriate data to build your formula.
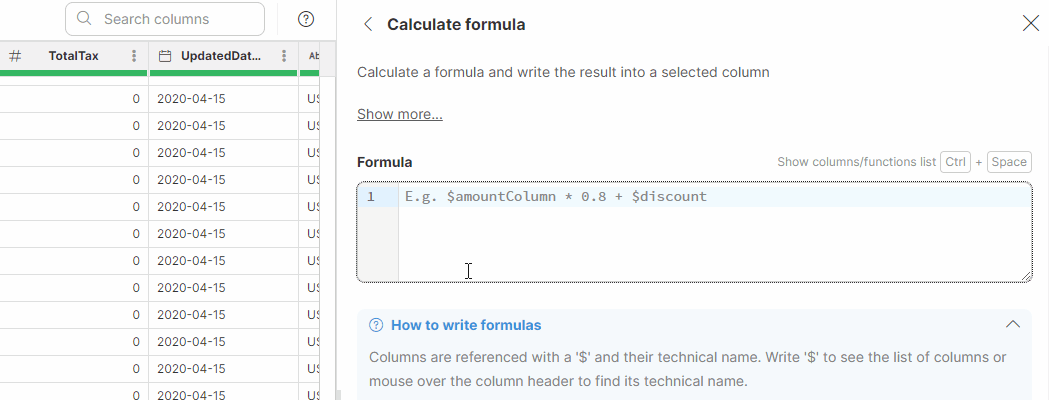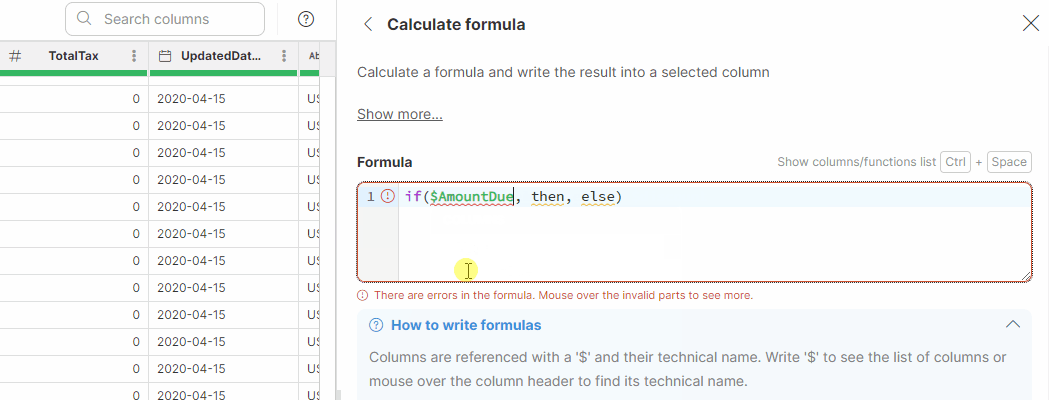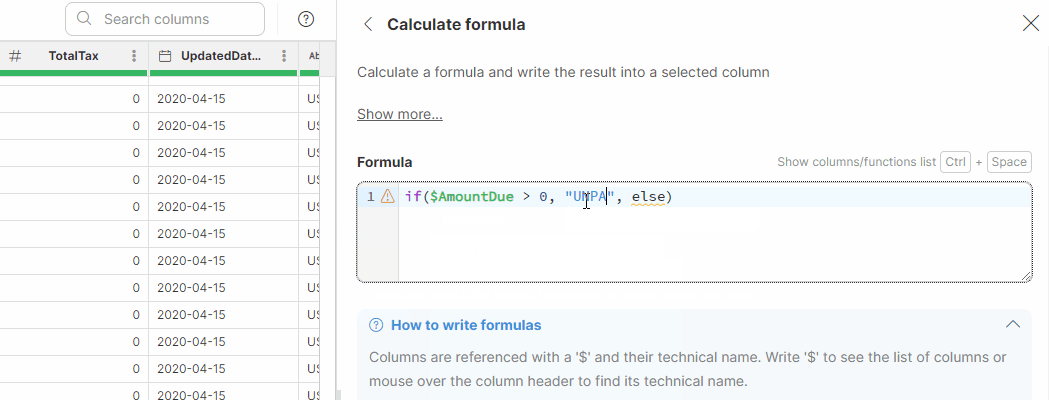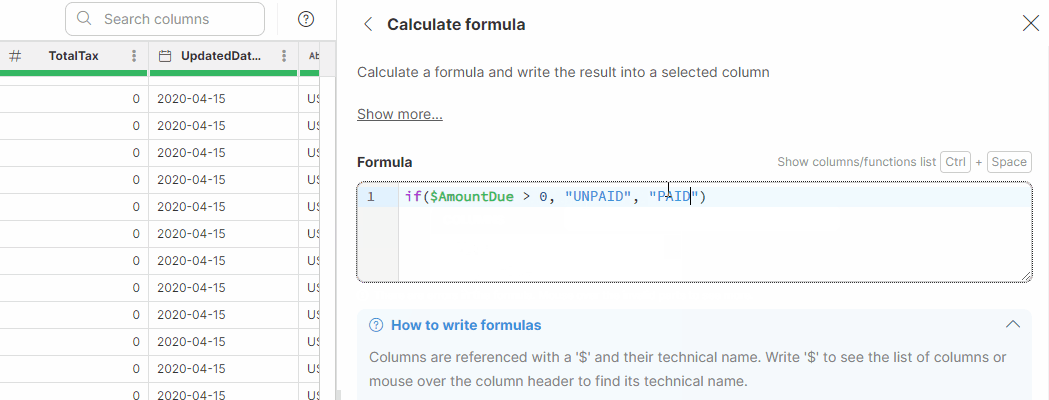
| Function | Description | Example formula | Result |
|---|---|---|---|
|
IF THEN ELSE |
|
|
|
Difference in two dates (use day, week, month, year, hour, minute, second, millisecond as unit) |
|
|
|
Returns |
|
Returns |
|
Converts the specified string to lowercase |
|
E.g. the text RED Apple will be converted to |
Functions can also be combined, e.g. to convert values to lowercase and look for the values that include the word "green" in them, the formula would like as follows:
contains(lowerCase($Contact), "green")
For a list of existing date functions refer here.
For a list of existing string functions refer here.
For a list of existing conversion functions refer here.
Modify values based on a condition
| You can also use step or group conditions to easily control when data transformations are applied. For more information, see Step and group conditions. |
In many transformations you’ll need to test your data and use different values in your formula depending on the result of the test. Wrangler formulas offer two ways of doing this - either with if function or with ternary operator.
if function
if function allows you to test a condition and return a value depending on whether the condition evaluated to true or false. Two variants are provided:
-
if(condition, value_if_true) -
if(condition, value_if_true, value_id_false)
The parameters in the function:
-
conditionis a boolean expression - the test you want to run -
value_if_trueandvalue_if_falseare expressions that are calculated depending on the result of the test. Both must return the same data type.
The first form of the function is useful when you only need to react when the condition is true. That way if condition is met, the function returns value_if_true.
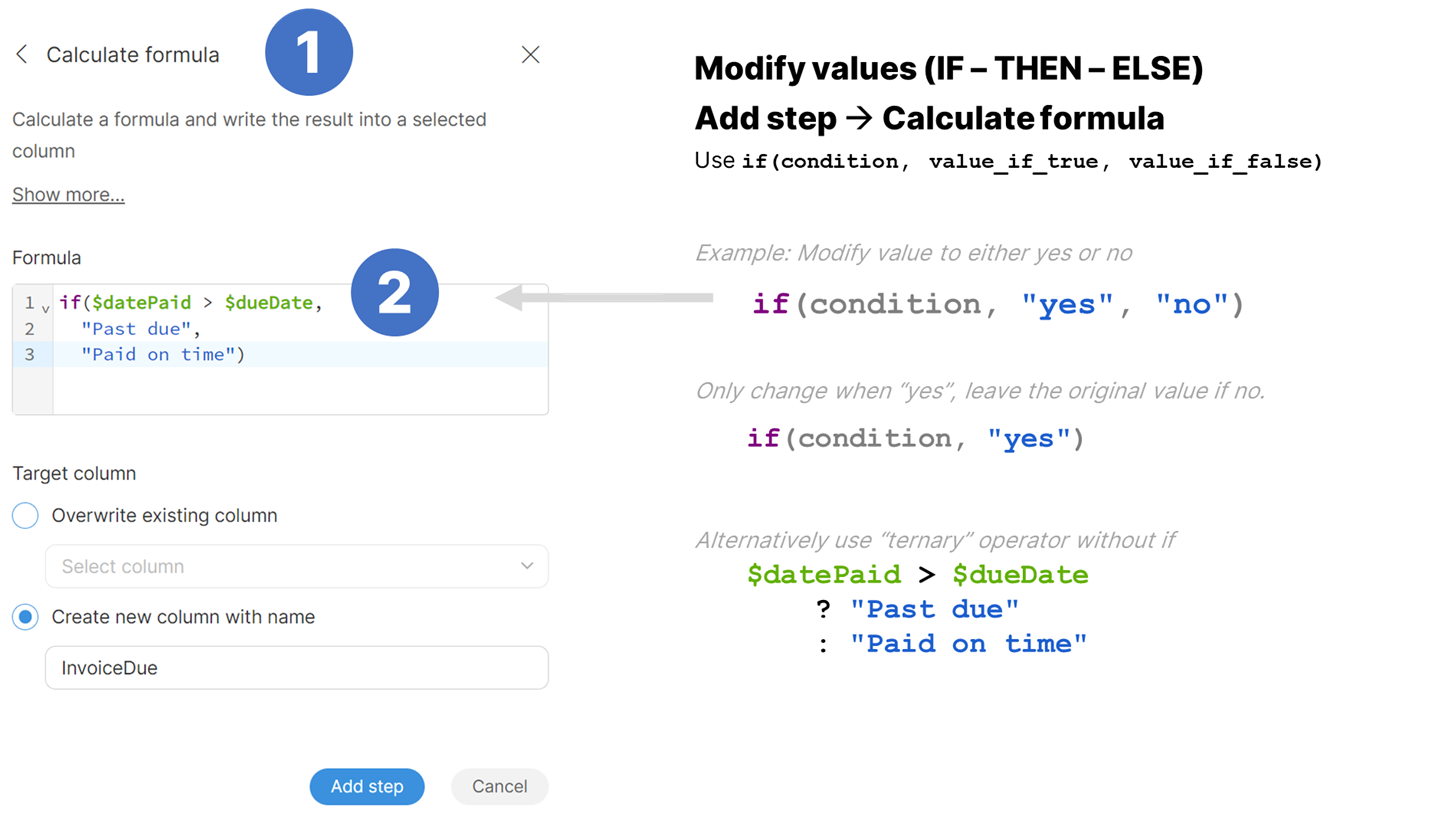
Examples:
-
Return "USD" currency code if no currency code is provided or if exchange rate is 1:
if($currencyCode == "USD" OR $exchangeRate == 1.0, "USD") -
Use
if($datePaid > $dueDate, "Past due", "Paid on time")to return either "Past due" for invoices paid after their due date or "Paid on time" for invoices paid before their due date. -
You can also nest
iffunctions to create more complex formulas:if($Total < 20000, "Low", if($Total < 50000, "Medium", "High")). This expression will return one of "Low", "Medium" or "High" dependig on the value of $Total column.
Ternary operator
Second way of getting the same result is a ternary operator ?. Its syntax is the following:
condition ? value_if_true : value_if_false
In this case, both value_if_true and value_if_false have to be present. Same examples as above written using ternary operator:
-
$currencyCode == "USD" OR $exchangeRate == 1.0 ? "USD" : $currencyCode(this assumes that the result is written into the $currencyCode column) -
$datePaid > $dueDate ? "Past due" : "Paid on time" -
$Total < 20000 ? "Low" : ($Total < 50000 ? : "Medium" : "High")Note the use of parenthesis to make the expression easier to read.
Both ways lead to the same result and it is up to you to use whichever you are more comfortable with.
Working with strings (text)
String is one of the most common types of data. Wrangler supports quite a few steps that work with string data - see more details in Text manipulation steps.
When working with string values in formulas, you have two options of how to write them - either with double quotes or with single quotes. The following represent the same strings in your formulas:
-
"test" -
'test'
String columns can have two different types of empty values (null values shown as No value and an empty string). See No value: Working with null and empty values for more information.
When working with strings, string comparisons are sensitive to white-spaces and letter case. So "TREE" is not the same as "tree" and "blue car" is not the same as "blue car" (multiple spaces between words).
For a list of string functions refer here.
Working with decimals (including currency)
Currency is represented as a decimal column with corresponding formatting on a column.
-
Right-click → Convert column to Decimal to change the column data type to decimal if it is a different data type.
-
Right-click → Change display format… to choose the correct format and update the currency symbol if needed.
To see the values in their unformatted form, set the display format to No specific format.
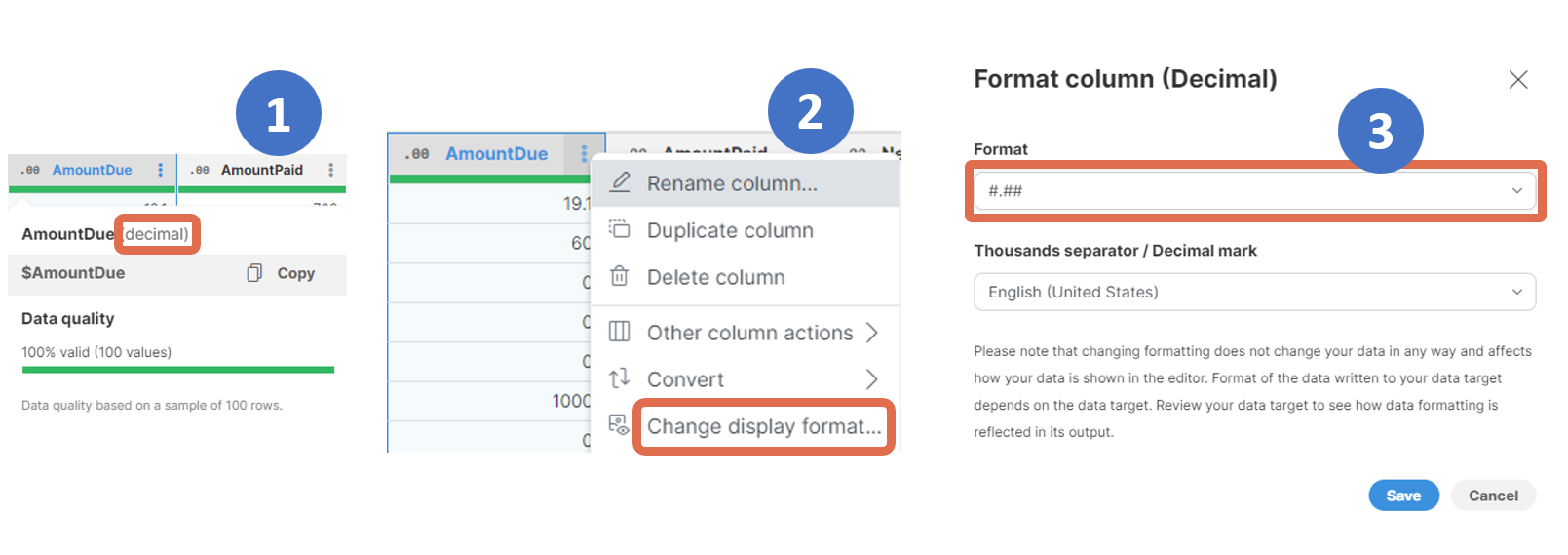
Things to bear in mind when working with decimals:
-
Wrangler always operates on full decimal precision (10 decimal places) regardless of the display format.
-
When writing decimal values in formulas, you must not use any digit grouping and you must use period as decimal point. For example, you cannot write
123 456,5and must write the number as123456.5.
Working with dates
Wrangler defines a single date type which stores both date and time with millisecond precision. If you wish to write date value in a formula, you can use syntax yyyy-MM-dd for dates or yyyy-MM-dd HH:mm:ss.SSS for full date and time.
For example, these are all valid date values:
-
2023-01-01- date only, time is set to midnight -
2023-01-01 14:45:30- date and time, milliseconds are not specified so will be 0 -
2023-01-01 14:45:30.123- full date and time with millisecond precision
You can use this syntax when writing date and time values in your formulas or in steps that require you to enter a date value (e.g., Replace empty value step).
When working with dates, you can take advantage of one of the following steps:
-
Current date and time step sets all fields in a date column to the current date and time. All fields are populated with the same date and time.
-
Date add/subtract step adds or subtracts time units (years, months, weeks, days, hours, minutes, seconds, or milliseconds) to / from date values. This step can help you quickly calculate new dates, for example, to calculate invoice due dates based on payment terms.
-
Date difference step calculates the time difference between two dates in a given time unit (days, weeks, months, years, hours, minutes, seconds, or milliseconds). This step allows you to quickly calculate, for example, the number of days between invoice creation and invoice payment.
-
Get part of date step extracts the specified time unit (day of week, day of month, month, year, hours, minutes, seconds, milliseconds) from a date column. You can, for example, use this step to extract the month from invoice dates from the past year and use it to create statistics of sales per month.
You can also extract the whole part of a date using one of the following functions in the Calculate formula step step:
-
extractDate($date)to return just the date part of the value (time is set to 0:00:00.000) -
extractTime($date)to return just the time. Since there can be no date value without the date part, the result will have the date part set to 1970-01-01 (the beginning of the Unix epoch).
Errors in your data
Errors (or invalid values) occur when the underlying data doesn’t match the column data type, or when you use validation steps to find values that do not match your criteria.
To correct errors:
-
Convert the column to string or other better suited data type (right-click → Convert)
-
Use the Fix errors menu to remove erroneous values or rows or replace errors with new values.
For more information on error handling refer to the Error handling in Wrangler section.
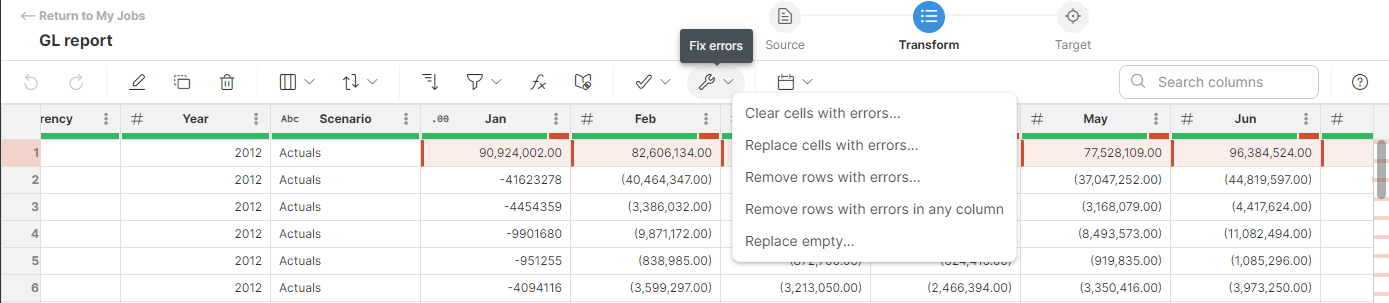
Depending on your target configuration, all rows where a data error is found are either rejected and output to a reject file when you run the job, or the job fails on the first error.
No data or some missing?
If you don’t see the data you expect, it might be caused by the limited size of the preview data. This is not an error, and you can continue working, only with limited visibility into the preview data.
Run the job to process and see all the data in the result.
How to work around the preview size limitation:
-
Keep adding steps as you need, regardless of the empty grid and warning message.
-
Run the job and inspect the full results in the target Excel/CSV.
-
You might want to apply some filters that limit the number of records you can see as the very last steps of your job.
No value: Working with null and empty values
The No value label (in italics) indicates that a cell is empty (will show as empty in the target, depending on how it handles empty values).
In formulas, No value is represented with the null keyword (case sensitive).
Note that for string columns there are two different empty values - a null value, which comes up as No value in fields, and an empty string (i.e., a string with zero length), which comes up as an empty field in Wrangler. They do not represent the same data and when writing your formulas you’ll need to make sure you handle both cases if needed. To work with empty strings, use two straight (double or single) quotes: "" or ''

In formulas you can use function isBlank which can determine if a string is empty - it will return true for strings that are null, empty or contain only whitespaces.
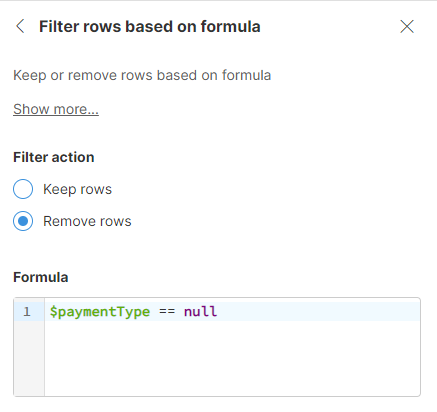
Example to remove null values:
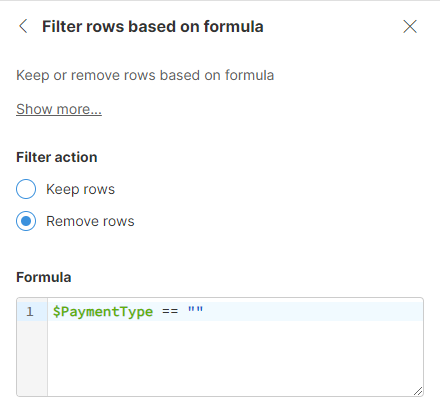
Example to remove empty string values:
Replacing empty value with a default value
In many cases you may want to replace empty value of given column with a default value. This can be done via Replace empty values step. This step will allow you to use single value instead of all empty values in selected column.
Note that this step will correctly handle string data - both null and empty string will be replaced with the value you provide.
If you wish to dynamically compute the new value, you will have to use Calculate formula step. The best way to do this is to use if function which has the following syntax:
if(condition, value_if_true)
The function returns value_if_true if the condition is satisfied (i.e., if the condition evaluates to true for given row). This is what you can effectively use to replace empty values. For example, to use USD as a default currency, you can do this:
if(isBlank($currencyCode), "USD")
isBlank function is a CTL function that returns true if a string value is null, empty string or contains just spaces. If the condition is not met, original value remains in the column.
if function also has a second variant with one extra parameter:
if(condition, value_if_true, value_if_false)
See below for more details on how to use if function.
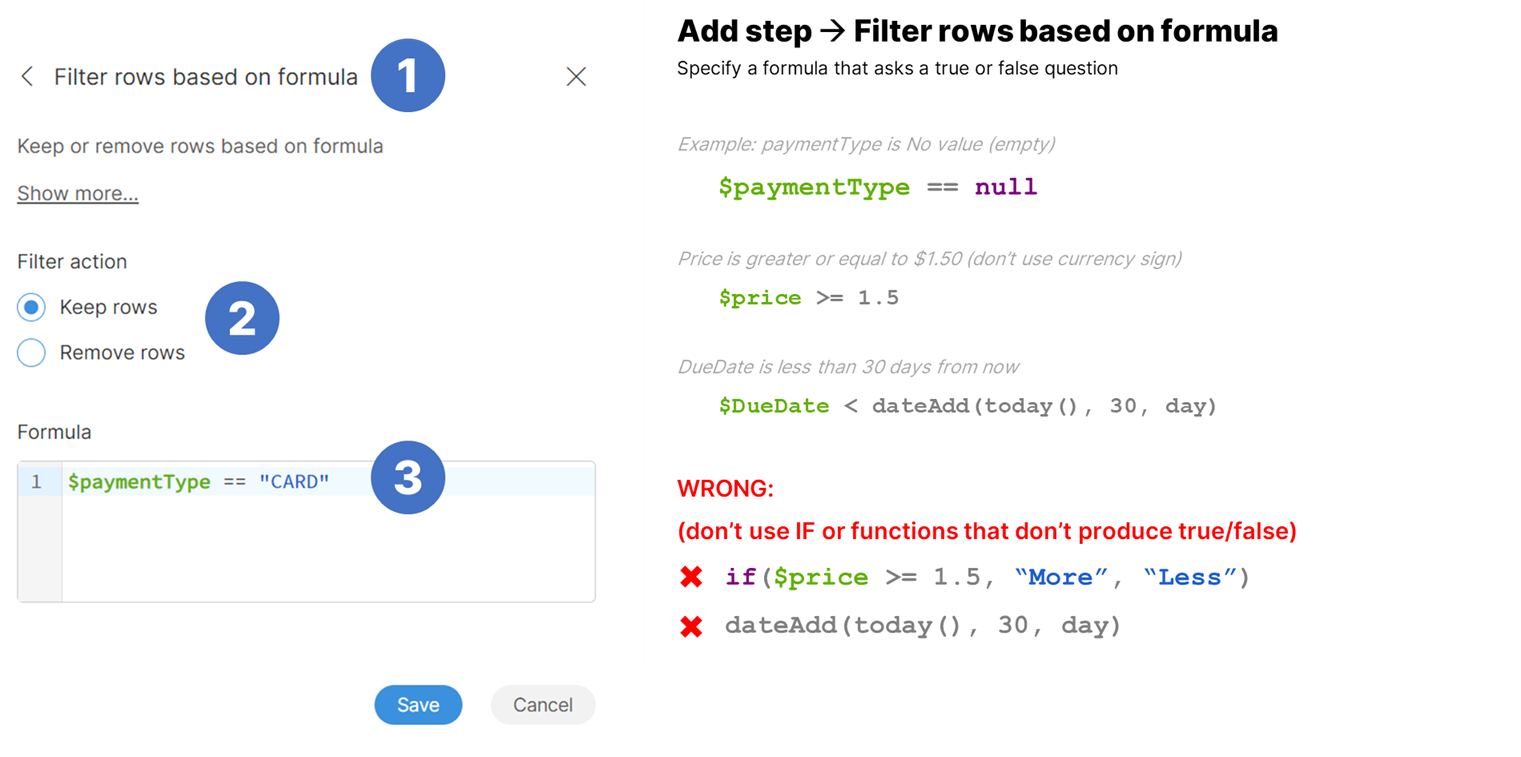
Filtering data
To filter your data, use the Filter rows based on formula step.
Getting results from your job
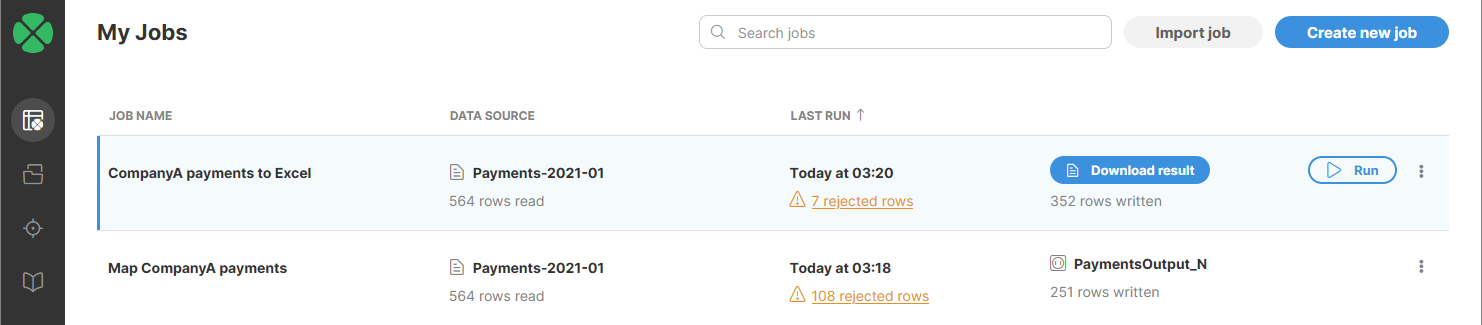
To get the complete results from your job, you first have to run the job via the Run button either from the job editor or from My Jobs page. Running the job will process all the data from the data source rather than just a sample.
Then depending on the data target, you will either be able to download the resulting file or the data will be written directly into the target. You can see the difference on the screenshot below - the first job called CompanyA payments to Excel uses Excel data target and therefore produces a file you can download via Download result button.
The second job uses a data target from Data Catalog. This target does not produce a file but rather writes the data into a Snowflake database (a target from Data Catalog can write to any system). As such, there is no file to download and you will need to use external tools to check the results in your Snowflake instance.
Note that in both cases you can download a reject file. This can downloaded from a status dialog shown when you click on the orange "rejected rows" link. See more details about job status and the status dialog here.
Target: Configuring job output
Data target defines the location where the data is written to. When a new job is created, a CSV target file is automatically generated and assigned as the target. The assigned data target can be changed as needed; for more information on how to update the target in an existing job, refer here.
A target can be:
-
a CSV file uploaded to Wrangler under My Targets
-
an Excel file uploaded to Wrangler under My Targets
-
a custom data target connector added to My Targets from the Data Catalog.
To change your data target settings, click on the Target button in the overview diagram of your job at the top of the transformation editor screen or click on the ![]() icon which appears when you hover over the Target step.
icon which appears when you hover over the Target step.

Your currently used target will be automatically selected and its details displayed on the right side. To change the configuration of your target, click on the Edit button next to Configuration.
To select a different target, select the desired target from the list, click on the Select ⟶ button, and confirm your changes.
CSV and Excel target files can be downloaded from the My Jobs page once a job has finished successfully. Data target connectors do not generate an output file and write data directly into the configured target within the connector (e.g., a database or a third-party interface like Hubspot or Xero).
See Data targets for more information on how to add targets to My Targets or how to change your target configuration.
Mapping your data to specific target
Targets created from the Data Catalog may require specific data formats. These targets may have required and optional columns that you can map into when building your data transformation. Jobs that use such targets will show a special Mapping step at the end of the step list in job editor.
This mapping step can be configured in a special Mapping view. This view offers functionalities to map either constant values or columns from your data preview to the target system. By creating a "link" between these elements, you essentially define how your data will be written into the corresponding target columns.
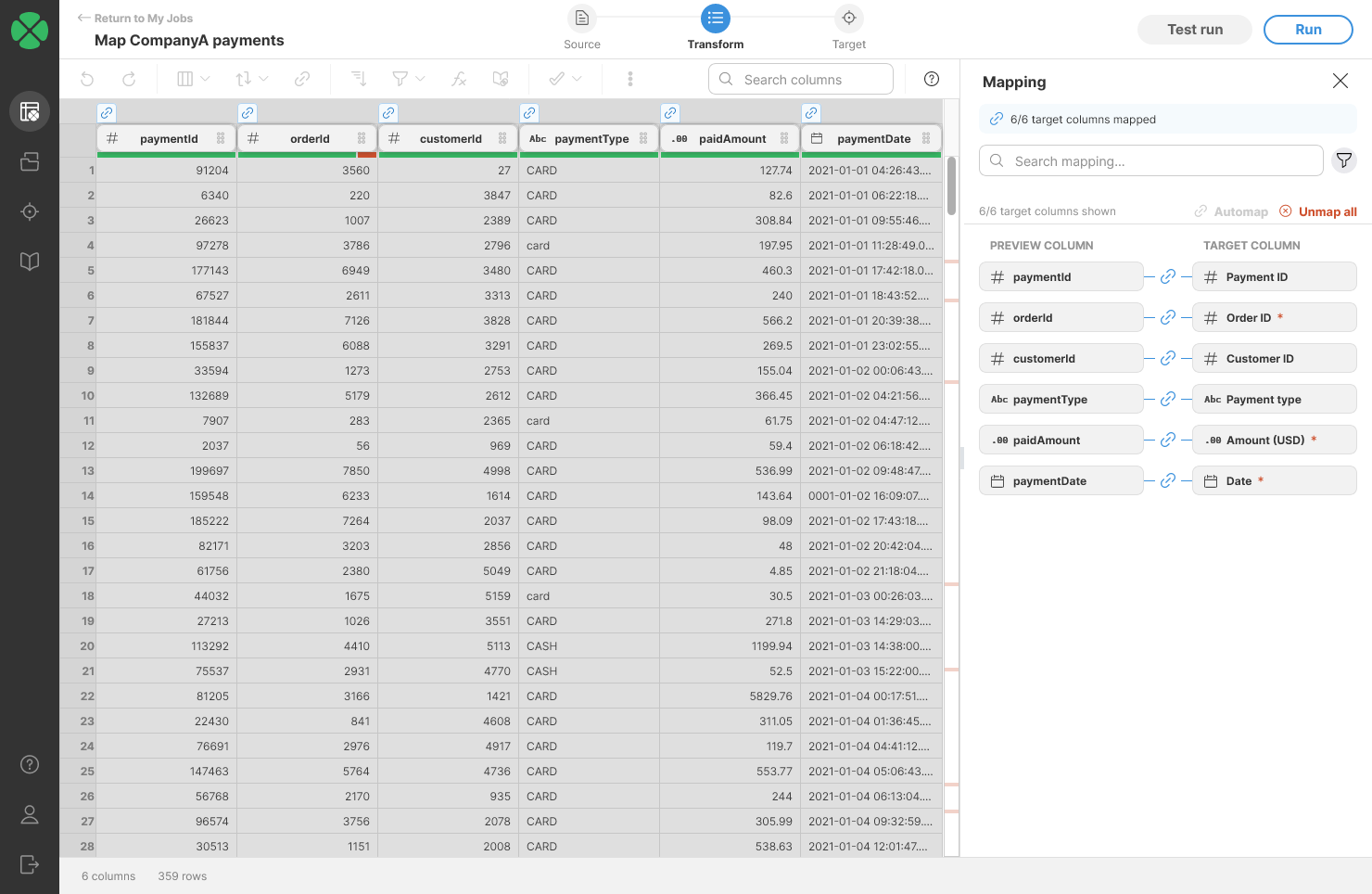
To learn more about how to work with your data in the Mapping mode, refer to Target mapping section.