Version
Hadoop Connections
Hadoop connection enables CloverDX to interact with the Hadoop distributed file system (HDFS), and to run MapReduce jobs on a Hadoop cluster. Hadoop connections can be created as both internal and external. See sections Creating Internal Database Connections and Creating External (Shared) Database Connections to learn how to create them. The definition process for Hadoop connections is very similar to other connections in CloverDX, just select Create Hadoop connection instead of Create DB connection.
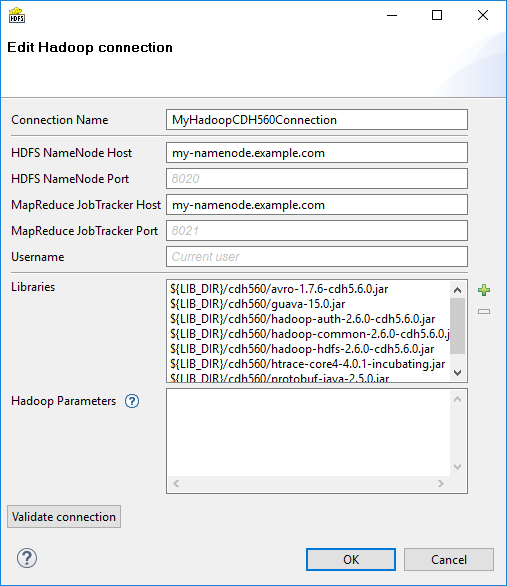
Figure 203. Hadoop Connection Dialog
From the Hadoop connection properties, Connection Name and HDFS NameNode Host are mandatory. Also Libraries are almost always required.
- Connection Name
-
In this field, type in a name you want for this Hadoop connection. Note that if you are creating a new connection, the connection name you enter here will be used to generate an ID of the connection. Whereas the connection name is just an informational label, the connection ID is used to reference this connection from various graph components (e.g. in a file URL, as noted in Reading of Remote Files). Once the connection is created, the ID cannot be changed using this dialog to avoid accidental breaking of references (if you want to change the ID of already created connection, you can do so in the Properties view).
- HDFS NameNode Host & Port
-
Specify a hostname or IP address of your HDFS NameNode into the HDFS NameNode Host field.
If you leave the HDFS NameNode Port field empty, the default port number 8020 will be used.
- MapReduce JobTracker Host & Port
-
Specify a hostname or IP address of your JobTracker into the MapReduce JobTracker Host field. This field is optional. If you leave it empty, CloverDX will not be able to execute MapReduce jobs using this connection (access to HDFS will still work though).
If you don’t fill in the MapReduce JobTracker Port field, the default port number 8021 will be used.
- Username
-
The name of the user under which you want to perform file operations on the HDFS and execute MapReduce jobs.
-
HDFS works in a similar way as usual Unix file systems (file ownership, access permissions). But unless your Hadoop cluster has Kerberos security enabled, these names serve rather as labels and avoidance for accidental data loss.
-
However, MapReduce jobs cannot be easily executed as a user other than the one which runs a CloverDX graph. If you need to execute MapReduce jobs, leave this field empty.
The default Username is an OS account name under which a CloverDX transformation graph runs. So it can be, for instance, your Windows login. Linux running the HDFS NameNode doesn’t need to have a user with the same name defined at all.
-
- Libraries
-
Here you have to specify paths to Hadoop libraries needed to communicate with your Hadoop NameNode server and (optionally) the JobTracker server. Since there are some incompatible versions of Hadoop, you have to pick one that matches the version of your Hadoop cluster. For detailed overview of required Hadoop libraries, see Libraries Needed for Hadoop.
For example, the screenshot above depicts libraries needed to use Cloudera 5.6 of Hadoop distribution. The libraries are available for download from Cloudera’s web site.
The paths to the libraries can be absolute or project relative. Graph parameters can be used as well.
TROUBLESHOOTINGIf you omit some required library, you will typically end up with
java.lang.NoClassDefFoundError.If an attempt is made to connect to a Hadoop server of one version using libraries of different version, an error usually appear, e.g.:
org.apache.hadoop.ipc.RemoteException: Server IPC version 7 cannot communicate with client version 4.Usage on CloverDX ServerLibraries do not need to be specified if they are present on the classpath of the application server where the CloverDX Server is deployed. For example, in case you use Tomcat app server and the Hadoop libraries are present in the
$CATALINA_HOME/libdirectory.If you do define the libraries paths, note that absolute paths are absolute paths on the application server. Relative paths are sandbox (project) relative and will work only if the libraries are located in a shared sandbox.
- Hadoop Parameters
-
In this simple text field, specify various parameters to fine-tune HDFS operations. Usually, leaving this field empty is just fine. See the list of available properties with default values in the documentation of
core-default.xmlandhdfs-default.xmlfiles for your version of Hadoop. Only some of the properties listed there have an effect on Hadoop clients, most are exclusively server-side configuration.Text entered here has to take the format of standard Java properties file. Hover mouse pointer above the question mark icon for a hint.
Once the Hadoop connection is set up, click the Validate connection button to quickly see that the parameters you entered can be used to successfully establish a connection to your Hadoop HDFS NameNode. Note that connection validation is not available if the libraries are located in a (remote) CloverDX Server sandbox.
|
HDFS fully supports the append file operation since Hadoop version 0.21.0 |