17. List of Configuration Properties
Below you can find the configuration properties available in CloverDX Server. The properties can be configured using the Setup GUI or by directly editing one of the several configuration sources.
In CloverDX Server UI, you can view the properties and their values in Configuration > CloverDX Info > Server Properties.
Additional properties used for Cluster configuration can be found in Cluster Configuration.
|
Configuration property and system property are not the same. Configuration properties can be configured in Setup section or in |
General Configuration Properties
| Key | Description | Default Value |
|---|---|---|
Absolute path to location of a CloverDX Server configuration file |
/absolute/path/to/cloverServer.properties |
|
Absolute path to an XML file containing exported CloverDX Server configuration (users, schedulers, event listeners, data services, etc.). If the property is set and the target file exists, it is automatically imported during the first startup with an empty database. Any error during the import causes CloverDX Server startup to fail. The property is not set by default. |
empty |
|
By default, this property is commented out and has a dynamically computed value: path containing If defined by the user, value has a higher priority. The property can be overridden using: environment variable context parameter or system property |
${user.data.home}/CloverETL or ${user.data.home}/CloverDX |
|
Absolute path to location of a CloverDX Server license file (license.dat) |
||
A comma-separated list of web-app contexts which may contain license. Each of them has to start with a slash! Works only on Apache Tomcat. |
/clover-license,/clover_license |
|
location of a CloverDX engine configuration properties file |
properties file packed with CloverDX |
|
This property may contain an absolute path to some "source" of additional CloverDX engine plugins. These plugins are not a substitute for plugins packed in WAR. "Source" may be a directory or a zip file. Both, a directory and a zip, must contain a subdirectory for each plugin. Changes in the directory or the ZIP file apply only when the server is restarted. For details see Extensibility - CloverDX Engine Plugins. |
empty |
|
sandboxes.home |
This property is primarily intended to be used as a placeholder in the sandbox root path specification. So the sandbox path is specified with the placeholder and it’s resolved to the real path just before it’s used. The sandbox path may still be specified as an absolute path, but placeholder has some significant advantages: * sandbox definition may be exported/imported to another environment with a different directory structure * user creating sandboxes doesn’t have to care about physical location on the filesystem * each node in Cluster environment may have a different "sandboxes.home" value, so the directory structure doesn’t have to be identical For backward compatibility, the default value uses the content of the clover.home configuration property. |
${clover.home}/sandboxes |
true | false If it is set to false, then the path relative to a sandbox root may point out of the sandbox. No file/folder outside of the sandbox is accessible by the relative path otherwise. |
true |
|
If enabled, the Server scans the |
false |
|
libraries.home |
The storage for unpacked Libraries. It must be accessible from all cluster nodes, so by default, it is a sub-directory of |
${sandboxes.home}/libraries |
Set this explicitly to JNDI if you need CloverDX Server to connect to a DB using JNDI datasource. In such case, "datasource.jndiName" and "jdbc.dialect" parameters must be set properly. Possible values: JNDI | JDBC |
JDBC |
|
JNDI location of a DB DataSource. It is applied only if "datasource.type" is set to "JNDI". |
java:comp/env/jdbc/clover_server |
|
class name for JDBC driver name |
||
JDBC URL used by CloverDX Server to store data |
||
JDBC database user name |
||
JDBC database password |
||
hibernate dialect to use in ORM |
||
SQL dialect for quartz. Value is automatically derived from "jdbc.dialect" property value. |
||
Enables/disables the job queue. See Job Queue for more details about job queue. |
true |
|
Enables/disables processing of Data Services by the job queue. By default Data Services are not processed by the job queue, see Job Queue Impact for more details. |
false |
|
System CPU load that is considered high and job queue will start enqueuing jobs, see Job Queue Load Metrics for more details. The value 0.85 means 85% system CPU load. This property can be used to tweak the CPU load threshold from which jobs will be enqueued. |
0.85 |
|
Usage of JVM heap memory in Server Core that is considered high and job queue will enter emergency mode, see Job Queue Emergency Mode for more details. The value 0.9 means 90% use of heap memory. This property can be used to tweak the Server Core heap memory usage threshold from which job queue will enter emergency mode. |
0.9 |
|
Usage of JVM heap memory in Worker that is considered high and job queue will enter emergency mode, see Job Queue Emergency Mode for more details. The value 0.9 means 90% use of heap memory. This property can be used to tweak the Worker heap memory usage threshold from which job queue will enter emergency mode. |
0.9 |
|
Maximum number of jobs that can be enqueued at one time - i.e. the maximum size of the queue. Each enqueued job consumes a small amount of memory, this property protects the CloverDX Server from running out of memory. |
100000 |
|
Time interval (in milliseconds) between each evaluation of job queue. This property defines how often the job queue processes enqueued jobs to be started, checks performance metrics etc. See Job Queue Algorithm for more details. |
100 |
|
The job queue starts enqueued jobs in batches, and load step defines the size of the batch (i.e.
number of jobs started at the same time). The load step is automatically adjusted by the job queue, and the |
20 |
|
The job queue starts enqueued jobs in batches, and load step defines the size of the batch (i.e.
number of jobs started at the same time). The load step is automatically adjusted by the job queue, and the |
5 |
|
The job queue starts enqueued jobs in batches, and load step defines the size of the batch (i.e.
number of jobs started at the same time). The load step is automatically adjusted by the job queue, and the |
300 |
|
Specifies the location of the OpenSSH configuration file which allows you to define SSH access outside of CloverDX Server.
The path to the file is |
||
List of properties and environment variables to be masked in the web UI, because they contain secrets. Note that the properties are also masked when accessed via the ServerFacade (e.g. from Groovy code). Changes in this list may cause unexpected behavior of server APIs that use the facade internally. |
*password*, security.secure_passwd.table.secure_passwd, cluster.jgroups.protocol.AUTH.value |
|
Session validity in milliseconds. When the request of logged-in user/client is detected, validity is automatically prolonged. |
14400000 |
|
Interval for exchange of invalid tokens in milliseconds. |
360000 |
|
Domain in which all new users are included. Stored in user’s record in the database. Shouldn’t be changed unless the "clover" must be white-labelled. |
clover |
|
List of features which are accessible using HTTP and which should be protected by Basic HTTP Authentication. The list has form of semicolon separated items; Each feature is specified by its servlet path. |
/request_processor;/simpleHttpApi;/downloadStorage;/downloadFile;/uploadSandboxFile;/downloadLog;/webdav |
|
Realm string for HTTP Basic Authentication. |
CloverDX Server |
|
List of features which are accessible using HTTP and which should be protected by HTTP Digest Authentication. The list has form of semi-colon separated items. Each feature is specified by its servlet path. Please keep in mind that HTTP Digest Authentication is feature added to the version 3.1. If you upgraded your older CloverDX Server distribution, users created before the upgrade cannot use the HTTP Digest Authentication until they reset their passwords. So when they reset their passwords (or the admin does it for them), they can use Digest Authentication as well as new users. |
||
Switch whether the A1 Digest for HTTP Digest Authentication should be generated and stored or not. Since there is no CloverDX Server API using the HTTP Digest Authentication by default, it’s recommended to keep it disabled. This option is not automatically enabled when any feature is specified in the security.digest_authentication.features_list property. |
false |
|
Realm string for HTTP Digest Authentication. If it is changed, all users have to reset their passwords, otherwise they won’t be able to access the server features protected by HTTP digest Authentication. |
CloverDX Server |
|
Interval of validity for HTTP Digest Authentication specified in seconds. When the interval passes, server requires new authentication from the client. Most of the HTTP clients do it automatically. |
300 |
|
The number of failed login attempts after which a next failed login attempt will lock the user. Set the value to 0 to disable the function. Since 4.8.0M1. |
5 |
|
Period of time in seconds during which the failed login attempts are counted. Since 4.8.0M1. |
300 |
|
Period of time in seconds after which a successful login attempt will unlock the previously locked user. Since 4.8.0M1. |
300 |
|
Enable/disable protection of Simple HTTP API and REST API against CSRF attacks, enabled by default.
The CSRF protection requires presence of the For more details, see CSRF Protection. |
true |
|
Enable/disable password policy for CloverDX users. The policy requires at least 8 characters and the password must contain both letters and digits (0-9). |
true |
|
SMTP server protocol. Possible values are "smtp" or "smtps". |
smtp |
|
SMTP server hostname or IP address |
||
SMTP server port |
||
true/false If it is false, username and password are ignored. |
||
SMTP server username |
||
SMTP server password |
||
Properties with the |
||
Used in log messages where it is necessary to name the product name. |
CloverDX |
|
Name of a default subdirectory for all server logs; it is relative to the path specified by system property "java.io.tmpdir". Don’t specify as an absolute path, use properties which are intended for absolute path. |
cloverlogs |
|
Enables logging of informations about server performance, e.g. memory and CPU usage. The name of the output file is "performance.log". It is stored in the same directory as other CloverDX Server log files by default. See Performance Log for more details. |
true |
|
Enables logging of operations called on ServerFacade and JDBC proxy interfaces. The name of the output file is "server-audit.log". It is stored in the same directory as other CloverDX Server log files by default. The default logging level is DEBUG so it logs all operations which may process any change. |
false |
|
Enables logging of Designer-Server calls. The name of the output file is "server-integration.log". It is stored in the same directory as other CloverDX Server log files by default. The default logging level is INFO. Username is logged, if available. JDBC and CTL debugging is not logged. |
true |
|
Location, where server should store Graph run logs. See Logging for details. |
${java.io.tmpdir}/[logging. default_subdir]/graph where ${java.io.tmpdir} is system property |
|
Pattern of the jobs' log messages |
%d %-5p %-3X{runId} [%t] %m%n |
|
Encoding of the jobs' log files |
UTF-8 |
|
Format of log that can be seen in Monitoring > Logs > Worker. |
||
Size of log that can be seen in Monitoring > Logs > Worker. |
||
Number of threads which are always active (running or idling). Related to a thread pool for processing server events. |
4 |
|
Max size of the queue (FIFO) which contains tasks waiting for an available thread. Related to a thread pool for processing server events. For queueCapacity=0, there are no waiting tasks, each task is immediately executed in an available thread or in a new thread. |
0 |
|
Max number of active threads. If no thread from a core pool is available, the pool creates new threads up to "maxPoolSize" threads. If there are more concurrent tasks then maxPoolSize, thread manager refuses to execute it. |
8192 |
|
Switch for idling threads timeout. If true, the "corePoolSize" is ignored so all idling threads may be time-outed |
false |
|
timeout for idling threads in seconds |
20 |
|
Max number of records deleted in one batch. It is used for deleting of archived run records. |
50 |
|
Prefix of archive files created by the archivator. |
cloverArchive_ |
|
A list of properties from a subset of properties, that may be used as placeholders and shall be resolved if used in paths. The properties can be used if you define a path to the root of a sandbox, or to locations of local or partitioned sandboxes, or path to a script, or path in archiver job. Users are strongly discouraged from modification of the property. The property name changed since CloverDX 4.2, however the obsolete name is also still accepted to maintain backwards compatibility. |
clover.home, sandboxes.home, sandboxes.home.local, sandboxes.home.partitioned, user.data.home |
|
It sets the maximal age in minutes before the record is removed from the database. The default is 1440 min = 24 h. |
1440 |
|
Used for Data Services jobs accessed through an HTTPS connector. It configures HTTP session inactivity timeout before the session is invalidated. The value is in minutes and its default is the same as HTTP session timeout for CloverDX Server web application. |
50 |
|
Enables or disables CORS filter. |
true |
|
A comma separated list of origins that are allowed to access Data Service endpoints. |
||
A comma separated list of HTTP methods that are allowed to access Data Service endpoints. |
||
A comma separated list of HTTP request headers that are allowed to access Data Service endpoints. |
||
A comma separated list of HTTP response headers that are allowed to be exposed on the client. |
||
A boolean indicating if the resource allows requests with credentials. |
false |
|
The number of seconds that preflight requests can be cached for by the client. |
||
Timeout for HTTP requests related to the Data App life-cycle such as login, retrieval of the model, etc. The value is in seconds. |
30 |
|
Timeout for the execution of the Data App (call of the Data Service). The value is in seconds. |
1800 |
|
Path to the branding resource ZIP file. See Branding of Data Apps. |
||
If |
true |
|
Time period (in seconds) after which the branding resources expire on the client (web browser).
Sent to the client as the |
604800 |
|
Limits the size of the data shown in the Data App response preview table for CSV format. The value is in MiB. |
100 |
|
Limits the number of table cells shown in the Data App response preview for CSV format. |
100000 |
|
Limits the size of metadata that can be used in the Data App response preview for CSV format. Metadata is sent to the client in an HTTP header. Most web servers have their own limitation on headers size. Make sure the limit is higher than the value of this property. |
6144 |
|
How often the Job Inspector refreshes job status (graph tracking) when the job is running, in milliseconds. |
5000 |
|
Timeout for HTTP requests from the Job Inspector to the REST API in milliseconds. |
30000 |
|
Used for failure indication of triggers (Schedule, Data Service endpoint or Event Listener) It represents the minimum number of invocations required to evaluate whether the percentage of failures is over the threshold. Ensures that during periods of low traffic the trigger does not switch to failing state. |
3 |
|
Enables or disables simple HTTP API. If the HTTP API is disabled, there is no link to HTTP API operations in login page and the HTTP API, the Available since 4.8.0M1. See Simple HTTP API. |
true |
|
Maximum depth for webDAV method PROPFIND. When the depth is not specified, the default is supposed to be infinite (according to the rfc2518), however it’s necessary to set some limit, otherwise the webDav client might overload the server filesystem. Also if the depth value specified by webDAV client in the request is higher than the pre-configured max depth, only the pre-configured maximum is used. |
40 |
|
Whether REST API returns absolute URLs to resources.
By default it returns absolute URLs (e.g. |
true |
|
Sets the required minimal heap memory threshold. If the configuration of CloverDX Server is set to less heap memory, a warning is displayed. Experienced users can change the default value to avoid the warning when running the server on a system with lower memory. The threshold is in megabytes. |
900 |
|
Sets the required minimal non-heap memory threshold. If the configuration of CloverDX Server is set to less non-heap memory, a warning is displayed. Experienced users can change the default value to avoid the warning when running the server on a system with lower memory. The threshold is in megabytes. |
256 |
|
Name of a default subdirectory for server tmp files; it is relative to the path specified by system property "java.io.tmpdir". |
clovertmp |
|
Since 3.0. It is a switch for backwards compatibility of passing parameters to the graph executed by a graph event. In versions prior to 3.0, all parameters are passed to executed graph. Since 3.0, just specified parameters are passed. Please see Start a Graph for details. |
false |
|
Interval of the timer, running file event listener checks (in milliseconds). See File Event Listeners (remote and local) for details. |
1000 |
|
The periodicity of Groovy checks for Groovy event listeners (in milliseconds). |
1000 |
|
The periodicity of Kafka consumer poll operation (in milliseconds). |
60000 |
|
Displays/hides the debug window. |
false |
|
The maximum time interval (in hours) for which the data in Performance Tab is recorded. Note: longer time intervals increase Server memory consumption and may increase latency when using Server GUI. |
24 |
|
A JMS Message Listener property. Sets the time (in milliseconds) for which a JMS message listener waits for a triggered task to finish. After this time, the listener continues in processing the next message from the source queue/topic. |
3600000 (1 hour) |
|
Sets the background color of the Instance Indicator. Possible values are: For the changes to take effect, you must log out and then back in the Server. |
||
Sets the label of the Instance Indicator. Note that too long label will be cropped in the GUI. For the changes to take effect, you must log out and then back in the Server. |
||
Value of the property is a version number.
If the version of CloverDX Server you are upgrading to is equal or less than the version, database patching will be started automatically.
Otherwise a user approval is required.
Example |
||
How often the Operations Dashboard refreshes its content, in milliseconds. |
3000 |
|
Timeout for HTTP requests from the Operations Dashboard to the REST API, in milliseconds. |
30000 |
|
Worker - Configuration Properties
| Key | Description | Default Value |
|---|---|---|
Enable/disable the Worker. To enable Worker, set to 1 (this is the default). To disable Worker and run all jobs in Core Server, set to 0. Starting more than one Worker is currently (in 4.9.0) not supported. |
1 |
|
Port range used for communication between Server Core and Worker and between Workers on different Cluster nodes. Communication between Server Core and Worker is done on localhost. Workers on different Cluster nodes communicate directly with each other over these ports - in Cluster setup, this port range should be open in firewall for other Cluster nodes.
If more Cluster nodes run on the same machine, make sure that there are enough free ports for Workers of all Cluster nodes on the machine.
The default configuration of |
10500-10600 |
|
Timeout before Worker startup is considered unsuccessful, after which Worker is stopped and restarted again. The timeout is in milliseconds. |
90000 |
|
Delay after Worker startup attempt ended with a failure, or a timeout, before another restart is attempted. The value is in milliseconds. |
3000 |
|
Timeout for connection initialization between Worker and Server Core, in both directions. The timeout is in milliseconds. This setting can be useful when handling communication issues between Server Core and Worker, typically under high load you might want to increase the timeout. |
60000 |
|
Read timeout for communication requests between Worker and Server Core, in both directions. If a request is not completely served before reaching this limit, the connection is terminated. The timeout is in milliseconds. This setting can be useful when handling communication issues between Server Core and Worker, typically under high load you might want to increase the timeout. |
600000 |
|
A directory with additional The Worker’s classpath is separate from Server Core (i.e. application container classpath). Any libraries needed by jobs executed on Worker need to be added on the Worker’s classpath. For backward compatibility, the default value uses the content of the clover.home configuration property. The property can contain paths to multiple directories. The separator between the directories can be a colon (on Linux and Mac) or semicolon (Linux, Mac and Windows), e.g.:
Some basic wildcards are supported: |
${clover.home}/worker-lib |
|
The maximum Java heap size of Worker in MB, it will be translated to the See our recommendations for heap sizes of Worker and Server Core. Setting to 0 uses Java default heap size (automatically determined by Java). This setting is not recommended for production usage. |
0 |
|
The initial Java heap size of Worker in MB, it will be translated to the Setting to 0 uses Java default initial heap size (automatically determined by Java). This setting is not recommended for production usage. |
0 |
|
Adds Java command line options for the Worker’s JVM. This property is useful to tweak the configuration of the Worker’s JVM, e.g. to tune garbage collector settings. These command line options override default options of the JVM. For example to enable parallel garbage collector: See Additional Diagnostic Tools section for useful options for troubleshooting and debugging Worker. |
||
Remote Java debugging of Worker, enables JDWP. Enabling this allows you to connect a Java debugger remotely to the running Worker process, to debug your Java transformations, investigate issues, etc. The port used by the debugger is determined dynamically and can be seen in the Worker section of the Monitoring or Setup page. |
false |
|
Sets whether system Java properties are inherited from the Server Core process to the Worker process. We automatically inherit some system properties to simplify the Worker configuration. For the list of system Java properties inherited from the Server Core to Worker, see properties passed from Server Core if worker.inheritSystemProperties is true. This functionality is enabled by default. Use this property to disable this behavior in case some of the inherited properties would cause issues. |
true |
|
Absolute path to the Java binary for Worker process, e.g. Use this property if you need to use a specific Java binary for running the Worker. Note: Make sure that Worker uses the same major Java version as the Server Core (e.g. Java 11). Using different major Java versions is not supported. |
Value is automatically determined based on $JAVA_HOME environment variable. |
Worker Health Related Properties
Below is a list of properties defining timeouts and limits related to the Worker’s health.
|
For Expert Users Only
These properties are for expert users only. Default values should be sufficient. Modification of the values could conceal the real cause of the problem; therefore, we strongly discourage users from changing the values. |
| Key | Description | Default Value |
|---|---|---|
Time before Worker is pronounced unresponsive because of a missing heartbeat (in milliseconds). |
120000 |
|
Time before Worker is pronounced unresponsive because it is not sending any information to Server Core (in milliseconds). |
60000 |
|
Time before Worker is pronounced unresponsive because all requests are failing (i.e. throwing exceptions) (in milliseconds). |
60000 |
|
Number of requests in a row which must fail to pronounce Worker unresponsive (amount of failures). |
30 |
|
Timeout for connection initialization from Worker to Server Core. Connection is used to send Worker heartbeat. The timeout is in milliseconds. |
5000 |
|
Read timeout for communication requests from Worker to Server Core. Connection is used to send Worker heartbeat. The timeout is in milliseconds. |
5000 |
Worker - JNDI Properties
The Worker has its own JNDI pool separate from the application container JNDI pool. If your jobs use JNDI resources (to obtain JDBC or JMS connections), you have to configure the Worker’s JNDI pool and its resources.
The worker JNDI properties must be configured using the clover.properties configuration file.
Libraries used by the JNDI resources must be added to the Worker’s classpath, see worker.classpath.
It is possible to define multiple datasources pointing to different databases or JMS queues, see examples below. The datasources are indexed in configuration, their properties have suffix [0], [1], etc. Even a single datasource must have the [0] index.
JDBC Datasources
Worker uses the Apache DBCP2 pool for its JNDI functionality.
Any DBCP2 configuration attribute is supported, see DBCP attributes.
The only mandatory properties are jndiName and url.
See table below for basic JNDI properties.
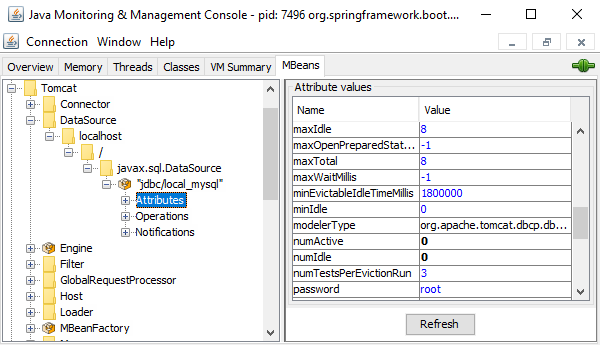
You can monitor the state of the datasources via JMX.
See Additional Diagnostic Tools for details on how to enable JMX on Worker.
Then you can connect to the Worker’s JMX interface with tools like jconsole and monitor the JNDI datasources, e.g.
for the number of currently open connections.
The related MBeans are under the Tomcat/DataSource/localhost///javax.sql.DataSource path:
| Key | Description | Example |
|---|---|---|
The name of the JNDI datasource. Mandatory. |
jdbc/database_name |
|
The JDBC connection URL. Mandatory. |
jdbc:postgresql://hostname:5432/database_name |
|
The user name for a database connection. |
clover |
|
The password for a database connection. The password value can be encrypted using the secure configuration tool, see Secure Configuration Properties. |
clover |
|
The database driver classname. The database driver must be on the Worker classpath, see worker.classpath. |
org.postgresql.Driver |
|
The maximum number of idle database connections in a pool. Set to -1 for no limit. |
10 |
|
The maximum number of database connections in a pool. Set to -1 for no limit. |
20 |
|
The maximum time Worker waits for a database connection to become available. In milliseconds, set to -1 for no limit. |
30000 |
|
If a connection is used both for reading and writing from and to the database set the property defaultReadOnly to false. Otherwise the connection reused from a pool could refuse to execute SQL statement writing data. |
||
Any DBCP2 attribute, e.g. |
The following example shows configuration of two JDBC Datasources.
worker.jndi.datasource[0].jndiName=jdbc/postgresql_finance
worker.jndi.datasource[0].url=jdbc:postgresql://finance.example.com:5432/finance
worker.jndi.datasource[0].maxIdle=5
worker.jndi.datasource[0].maxTotal=10
worker.jndi.datasource[0].maxWaitMillis=-1
worker.jndi.datasource[0].username=finance_user
worker.jndi.datasource[0].password=conf#eCflGDlDtKSJjh9VyDlRh7IftAbI/vsH
worker.jndi.datasource[0].defaultReadOnly=false
worker.jndi.datasource[0].driverClassName=org.postgresql.Driver
worker.jndi.datasource[1].jndiName=jdbc/MysqlDB
worker.jndi.datasource[1].url=jdbc:mysql://marketing.example.com:3306/marketing?useUnicode=true&characterEncoding=utf8
worker.jndi.datasource[1].maxIdle=10
worker.jndi.datasource[1].maxTotal=20
worker.jndi.datasource[1].maxWaitMillis=-1
worker.jndi.datasource[1].username=marketing_user
worker.jndi.datasource[1].password=conf#JWsMa2okg7Dq2gtLBM84sE==
worker.jndi.datasource[1].defaultReadOnly=false
worker.jndi.datasource[1].driverClassName=com.mysql.cj.jdbc.DriverJMS Connections
Worker can use any JMS broker to define JMS connections in JNDI.
Any JMS broker configuration attribute is supported.
The mandatory properties are jndiName, factory and type.
See table below for basic JNDI properties for JMS resources.
| Key | Description | Example |
|---|---|---|
The name of the JNDI JMS resource. Mandatory. |
|
|
Factory class for creating the JMS resource. This is JMS broker specific. Mandatory. |
|
|
Implementation class of the JMS resource. This is JMS broker specific. Mandatory. |
|
|
Configuration property for the JMS resource. Any configuration property supported by the JMS broker can be used. |
|
The following example shows configuration of several JMS resources.
worker.jndi.jms[0].jndiName=jms/CloverConnectionFactory
worker.jndi.jms[0].type=org.apache.activemq.ActiveMQConnectionFactory
worker.jndi.jms[0].factory=org.apache.activemq.jndi.JNDIReferenceFactory
worker.jndi.jms[0].brokerUrl=tcp://localhost:61616?jms.prefetchPolicy.queuePrefetch=1
worker.jndi.jms[0].brokerName=LocalActiveMQBroker
worker.jndi.jms[1].jndiName=jms/CloverQueue
worker.jndi.jms[1].type=org.apache.activemq.command.ActiveMQQueue
worker.jndi.jms[1].factory=org.apache.activemq.jndi.JNDIReferenceFactory
worker.jndi.jms[1].physicalName=TestQueueWorker - SSL Properties
In Cluster, Workers of each node communicate with each other directly for increased performance. This communication is used to transport data of Cluster remote edges in Clustered jobs between the nodes. For increased security, it is possible to use SSL for the remote edge communication.
SSL communication between Workers needs to be enabled and configured separately from SSL of the application container that runs Server Core.
The worker.ssl.enabled property is used to enable/disable SSL.
If a Cluster node’s "self" URL is using HTTPS, we automatically set the property to true.
Configuration of SSL consists of setting paths and passwords of KeyStore and TrustStore, see the table below for details.
Note that if the standard SSL related system properties (javax.net.ssl.keyStore, javax.net.ssl.keyStorePassword, javax.net.ssl.keyAlias, javax.net.ssl.trustStore and javax.net.ssl.trustStorePassword) are used to configure KeyStore/TrustStore for the Server Core, they are propagated to Worker; therefore, their respective worker.ssl properties do not need to be configured.
The properties containing passwords to the keystore and truststore files are encrypted before adding to Worker’s command line.
To avoid having the encrypted password properties on Worker’s command line completely, you may also specify path to a file which will be created on Worker’s start and these encrypted passwords will be stored in it (via the worker.ssl.passwordFile property).
Recommended steps to enable SSL for inter-worker communication are:
-
Enable SSL for each Cluster node, via the application container settings. Configure TrustStore and KeyStore via the standard
javax.net.ssl.*properties. -
Set
cluster.http.urlfor each node to point to its own HTTPS URL -
Check that communication between Cluster nodes over SSL works and that the nodes can correctly see each other. The Monitoring page of Server Console should show the whole Cluster group and its nodes correctly.
-
Worker should automatically inherit the above SSL configuration.
-
Run a Clustered job on Worker
| Key | Description | Example |
|---|---|---|
Enables or disables an SSL connection for Worker. Note that if the Server runs on HTTPS, SSL is enabled automatically; however, this property has a higher priority. |
|
|
Absolute path to the KeyStore file. |
path/to/keyStore.file |
|
The KeyStore password. |
||
The alias of the key in keyStore. Optional - the property does not have to be specified if there is only one key in the KeyStore. |
||
The absolute path to a file containing encrypted keystore and truststore passwords for Worker. Optional: by default this is not set, and the keystore and trusstore passwords are passed to Worker as command line arguments with encrypted values. Use this property to avoid having the encrypted passwords on Worker command line, but instead passed via the file. |
||
The port for SSL communication with Worker. The property is configured automatically and the value is set from worker.portRange. |
||
Disables validation of certificates in HTTPS connections of remote edges. Disabling the validation affects jobs run on both Worker and Server Core. |
|
Properties on Worker’s Command Line
To ensure proper functionality of CloverDX Worker, there is a number of parameters which can appear on its command line. These can be hard-coded, passed from the configuration file, propagated from Server Core or added manually for a specific purpose, see the list below.
Note that the list does not include internal system parameters not configurable by the user.
| Property | Note |
|---|---|
Passed from Server Core if worker.inheritSystemProperties is true |
|
-Djavax.net.ssl.trustStorePassword |
Standard SSL related properties. Values of the properties containing passwords are encrypted.
See also SSL properties for Worker. |
-Djavax.net.ssl.keyStorePassword |
|
-Djavax.net.ssl.keyStore |
|
-Djavax.net.ssl.trustStore |
|
-Djavax.net.ssl.keyAlias |
|
-Djava.library.path |
Standard Java properties |
-Djava.io.tmpdir |
|
-Dhttps.protocols |
|
-XX:MaxMetaspaceSize |
|
-Djava.rmi.server.hostname |
|
-Dfile.encoding |
The charset for file contents. |
-DsocksProxyHost |
Properties for proxy configuration. The properties with * are passed for http, https and ftp. |
-DsocksProxyPort |
|
-DsocksProxyVersion |
|
-Djava.net.socks.username |
|
-Djava.net.socks.password |
|
-Djava.net.useSystemProxies |
|
-D*.proxyHost |
|
-D*.proxyPort |
|
-D*.proxyUser |
|
-D*.proxyPassword |
|
-D*.nonProxyHosts |
|
-Duser.timezone |
|
-Duser.language |
|
-Duser.region |
|
-Duser.country |
|
-Duser.variant |
|
-Djdk.nio.maxCachedBufferSize |
Limits the memory used by the temporary buffer cache. Prevents memory leaks. |
-Xss |
Limits the maximum stack size of application threads. Reduces memory requirements. |
-XX:SoftRefLRUPolicyMSPerMB / -Xsoftrefthreshold |
Hints garbage collector to free softly referenced objects earlier. Improves garbage collector performance and reduces observable heap size. Only one of these properties is present based on used JVM implementation (Hotspot / OpenJ9). |
-XX:+UseG1GC |
Setting G1 garbage collector as default for Java 8. See garbage collector for Worker. |
--add-opens=java.base/java.lang |
Parameters for suppressing illegal reflective access warning. |
--add-opens=java.base/java.util |
|
--add-exports=java.xml/com.sun.org.apache.xerces.internal.parsers |
|
--add-opens=java.rmi/sun.rmi.transport |
|
--add-exports=java.base/sun.security.provider |
--add-exports=java.security.jgss/sun.security.krb5 |
-Xms*m |
From the |
-Xmx*m |
From the |
-agentlib:jdwp=transport=dt_socket,server=y,address=*,suspend=n |
From the worker.enableDebug property; * is a dynamically determined port used by the debugger. The port can be seen in the Worker section of the Monitoring or Setup page. |
-Dworker.ssl.passwordFile |
The absolute path to a file containing encrypted keystore and truststore passwords for Worker. See also SSL properties for Worker. |
-Dsecurity.config_properties.encryptor.providerClassName |
Encryption provider and algorithm for secure configuration properties. See Configuring application server. |
-Dsecurity.config_properties.encryptor.algorithm |
|
Added if SSL is enabled (see worker.ssl.enabled) |
|
-Dworker.ssl.port |
The port for SSL communication with Worker is taken from the port range set by the worker.portRange property. |
Added from |
|
-Dworker.ssl.keyStore |
Worker-specific SSL configuration properties. Values of the properties containing passwords are encrypted. If the standard SSL properties are used (see above), the Worker-specific properties don’t have to be configured. See also SSL properties for Worker. |
-Dworker.ssl.keyStorePassword |
|
-Dworker.ssl.keyAlias |
|
-Dworker.ssl.trustStore |
|
-Dworker.ssl.trustStorePassword |
|
Job Execution Properties
| Key | Description | Default Value |
|---|---|---|
An interval in milliseconds for scanning of a current status of a running graph. The shorter interval, the bigger log file. |
2000 |
|
Log level of graph runs. TRACE | DEBUG | INFO | WARN | ERROR |
INFO |
|
Defines maximal depth of the job execution tree, e.g. for recursive job it defines the maximal level of recursion (counting from root job). |
32 |
|
Amount of graph instances which may exist (or run) concurrently. 0 means no limits. |
0 |
|
Classpath for transformation/processor classes used in the graph. Directory [Sandbox_root]/trans/ does not have to be listed here, since it is automatically added to a graph run classpath. |
||
Disables check of graph configuration. Increases performance of a graph execution; however, it may be useful during graph development. |
true |
|
If true, more descriptive logs of graph runs are generated. |
true |
|
If true, the graph executor registers JMX mBean of the running graph. |
true |
|
If true, edges with enabled debug store data into files in debug directory. |
false |