Version
2. CloverDX Server Architecture
CloverDX Server is a Java application distributed as a web application archive (.war) for an easy deployment on various application servers. It is compatible with Windows and Unix-like operating systems.
CloverDX Server requires Java Development Kit (JDK) to run. We do not recommend using Java Runtime Environment (JRE) only, since compilation of some transformations requires JDK to function properly.
The Server requires some space on the file system to store persistent data (transformation graphs) and temporary data (temporary files, debugging data, etc.). It also requires an external relational database to save run records, permission, users' data, etc.
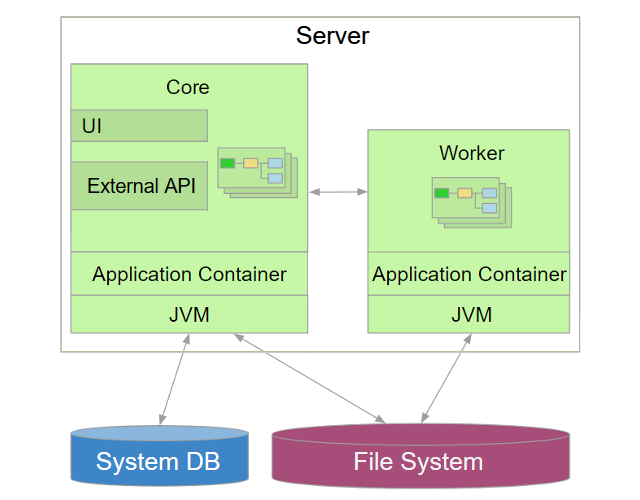
Figure 2. System Architecture
The CloverDX Server architecture consists of Core and Worker.
CloverDX Core
CloverDX Server's Core manages users and groups, checks permissions, schedules execution and provides management and monitoring UI. It provides APIs for other applications: Data Service API, HTTP API and Web Service API. For more information, see CloverDX Core.
CloverDX Worker
Worker is a separate process that executes jobs: graphs, jobflows and profiler jobs. The purpose of Worker is to provide a sandboxed execution environment. For more information, see CloverDX Worker.
Dependencies on External Services
The Server requires a database to store its configuration, user accounts, execution history, etc. It comes bundled with an Apache Derby database to ease the evaluation. To use CloverDX Server in production environment, a relational database is needed.
The Server needs a connection to an SMTP server to be able to send you notification emails.
Users and groups' data can be stored in the database or read from an LDAP server.
Server Core - Worker Communication
Server Core receives Worker’s stdout and stderr. The processes communicate via TCP connections.