Version
Data Sampling
This step allows you to select a sample of your data source and run profiling on it.
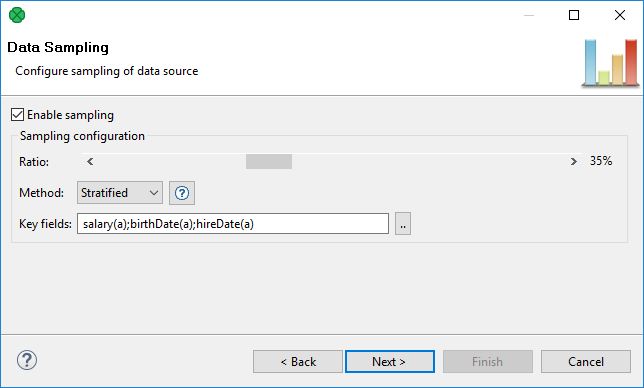
Figure 24. Data Sampling settings
If you leave Enable sampling unchecked, all your data will be analyzed. However, you might want to analyze only a certain part of it (especially in huge data sets) and run the analysis on representative samples of the whole data set. To achieve that, check Enable sampling and make further settings:
-
Ratio - the desired size of output data expressed as a fraction of the input (in per cent).
-
Method - to create a representative sample of the whole data set, choose one out of four available methods:
-
Simple - every record gets an equal chance of being selected. Useful when your data set has no particular structure (there are no known keys, no sort order). If you need to acquire just 'a sample' of the whole data, this is the method to use. Also, please note this is the only available method when profiling databases (see Database Table Profiling).
-
Systematic - useful in well-organized data sets with a key. You need to acquire a sample, but you cannot do it randomly because you would get a non-representative data probe. That is why you only start randomly and then keep on choosing records in equal steps - not to harm the information about the data set’s sort order. Example: let us have 5.000 employees of a company. Every employee gets the
hireDateattribute keeping the information about when they were hired. In order to cover all periods when employees were coming to the company, arrange the data set according tohireDate. Afterwards, when you perform Systematic sampling you can be sure you will not pick only employees having come to the company in the last month or at the beginning of its existence. -
Stratified - if the data set contains distinct categories, it can be organized by these categories into separate strata (e.g. men, currencies, kinds of animals). However, every such stratum is ill-organized and chaotic, it is not arranged at all. In consequence, you pick randomly from these strata - and always at least one record from each stratum. Example: let us have various currencies and their transactions. These are not arranged by any means. You would like to get a better understanding of transactions in individual currencies. That is where you will use Stratified sampling.
-
PPS (Probability Proportional to Size Sampling) - there are distinct categories according to which the data set can be arranged, too. In this case, however, strata are well organized and can be sorted according to a key. Example: let us have a few groups of currencies and sums of their transactions. Each group can be arranged according to those sums (thus preserving the minimum and maximum transaction). Next, Systematic sampling is applied on them. All transactions are therefore equally represented.
-
-
Key fields - field names the Method uses to define strata. It is required in all sampling methods except for Simple. If you click the … button, you can easily select key fields (and their sort order) in a separate window:
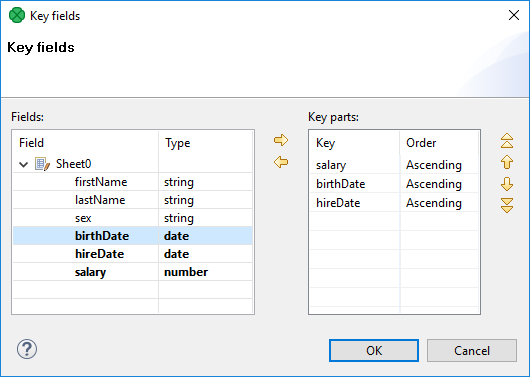 Figure 25. Selecting key fields
Figure 25. Selecting key fieldsIf you want to learn more about data sampling, consult, for example, the DataSampler component. For a deeper insight into individual sampling methods in statistics, see Wikipedia.