Version
4. Writing data in Wrangler
Wrangler allows you to write data to CSV files and to Microsoft Excel xlsx files. See below for more details about each data target.
Besides the two formats for valid rows, Wrangler can also produce a reject file - a file which stores information about rows which contained errors. Reject files use the same file type as the valid output (i.e., if your main output is CSV, reject file will be CSV as well). See details for each data target to see more about the reject file layout.
Downloading and viewing output files
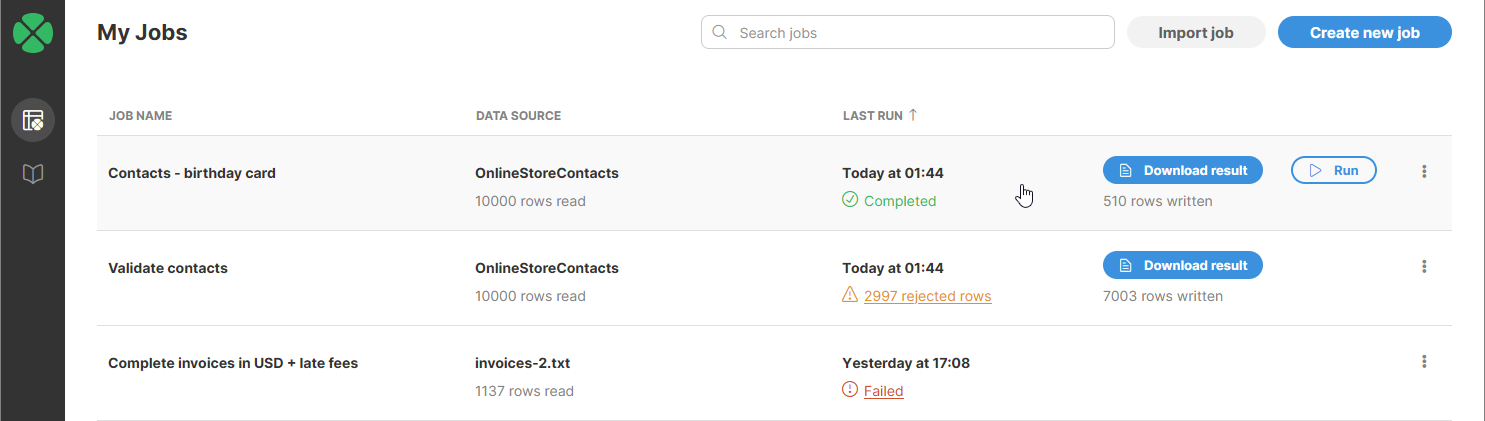
When files are written by Wrangler, they are stored in your workspace. You can download your files from Wrangler user interface from My Jobs screen by clicking on the arrow icon next to the output file name:
Figure 8. My Jobs screen showing information about three job runs.
|
As with files you upload, you can also see the output files via CloverDX Server Console in Sandboxes module. The files are located in your Wrangler workspace sandbox in |
Reject file format
Rejected rows are collected in a single file called "reject file". The file provides information about why each row was rejected including the data in the rejected row at the end of the transformation.
Reject files can be written in two different formats - as a CSV file (for CSV data target) or as XLSX file (for Excel data target). In both cases, the information in the file is the same and the only difference is the file format itself.
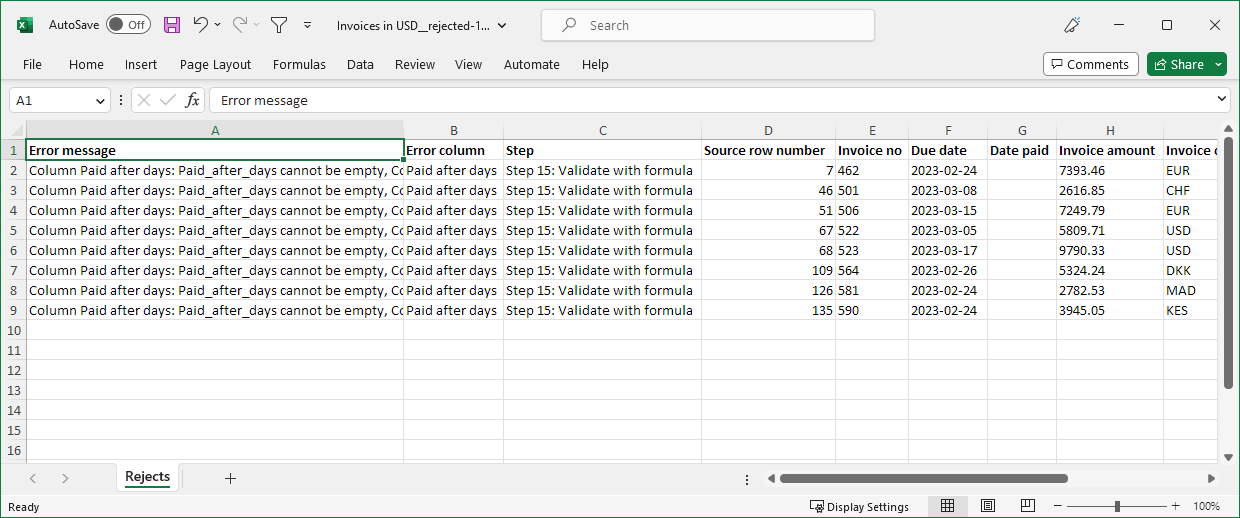
Figure 9. Example reject file in Microsoft Excel format
Reject file contains one row for each rejected row. Since there can be multiple errors in each row, all errors for given row are collected in the single reject file row.
Besides the error details, the reject file also contains the data that was rejected. The data is all stored as string columns to ensure that invalid values can be written to the reject file as well.
The reject file contains the following columns:
-
Error message (column A in Excel): full error message describing the errors in current row. If more than one error is present in a row, error messages are concatenated together. This means that the value can be quite long for rows with many errors.
-
Error column (column B): name of the column in which an error occurred. If there are multiple errors in current row, multiple column names are provided as semicolon-separated list.
-
Step (column C): description of a step in which an error that caused the row to be rejected occurred. If multiple errors are present in current row, multiple steps are listed here as semicolon-separated list. Each step is written as
Step N: step typewhereNis the number of the step in the step list (first step is 1) andstep typeis the "generic" name of the step. Example:Step 15: Validate with formulais 15th step in the job and it is a Validate with formula step. -
Source row number (column D): row number as it was read from the data source (regardless of the source type). The rows are numbered sequentially starting with 1 when they arrive from the data source. Sorting, filtering or removing rows does not change the Source row number value. This means that at the end of the transformation, the sequence of row numbers may be out of order or have gaps in it depending on transformation steps. The Source row number is useful to tie the data to what came from the source system and can help identify the rows in the source if data fix is required.
-
Data columns (columns starting with E): all columns after Source row number are data columns. Data is in the same layout as in the last step of the transformation. The only difference is that all columns are converted to string before they are written to the reject file. This is to ensure that even invalid values (e.g. with wrong format) can be output to the reject file.
CSV data target
CSV data target allows you to write your data into CSV files that are stored in your Wrangler workspace. To change settings of your data target, click on the Target in the overview diagram of your job at the top of the transformation editor screen:

Figure 10. Job diagram showing main parts of your Wrangler job
CSV data target configuration
Following settings are available for CSV data target:
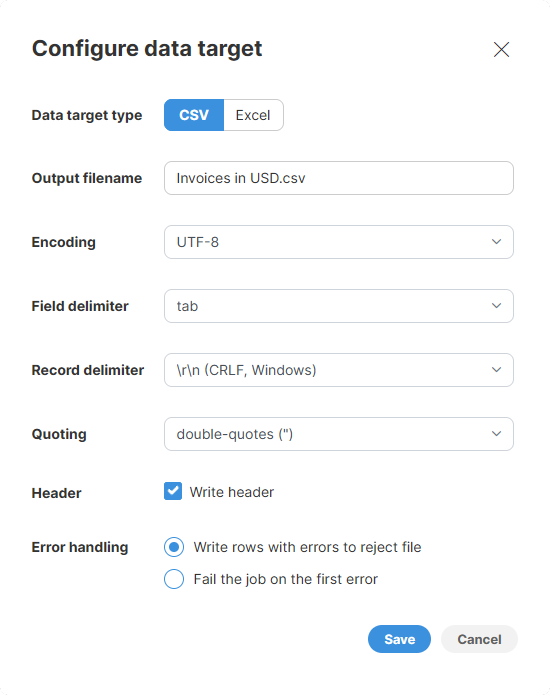
Figure 11. CSV data target configuration dialog
-
Output file name: name of the output file. Default value is the name of your Wrangler job with
.csvextension. -
Encoding: encoding for the output file. Default (recommended) value is UTF-8 which is an universal encoding that will allow you to save data in any language while making it readable in many other apps. Other common encodings include windows-1252 (US English encoding commonly used for files created on Windows) or ISO-8859-1 (US ASCII encoding). Selecting the wrong encoding here can produce a file in which some characters are not stored correctly.
-
Field delimiter: a single character to use as a separator between columns in the output file. You can either select one of the provided options or type your own character. Most common delimiter is either a comma or a tab.
-
Record delimiter: configures character(s) that are used to separate rows in the output file. The default value is a "Windows new line" which means that each row appears on a separate line in the output file. Select the option based on your target platform - if you are targeting Windows users, use Windows CRLF option, for Linux or Mac users pick Linux LF option. You can also type your own delimiter if needed.
-
Quoting: allows you to configure whether values in your file are surrounded by quotes or not. If you enable quotes, the data may look like this (assuming two columns:
NameandAge):"Name","Age" "Alice","22" "Bob","23"Quoting is needed when your data can contain your delimiter character - e.g., if your delimiter is a comma and your data can contain commas as well. When configuring quoting you can pick which character to use - whether double quotes or single quotes. Double quotes (the default value) are more common and recommended if quoting is needed.
-
Header: allows you to configure whether to write file header or not. If enabled, the file header will be written as the first row of the output and will contain labels of all columns in your data. We recommend enabling the header as that will allow data recipients to know what is in the data.
-
Error handling: determines what to do with rows that contain errors in any of their cells. Two options are provided:
-
Write rows with errors to reject file (default value): if selected, all rows that contain errors are written to a reject file. Reject file allows you to see the rejected rows as well as information about errors that caused those rows to be rejected (read more here). You can then see number of rows that were rejected on My Jobs page when job execution ends:

-
Fail the job on the first error: when an error is encountered when writing the file, the job is stopped and the error will be reported on My Jobs page:

-
CSV data target limitations
CSV target will allow you to work with any size of data - unlimited number of rows or columns. It does not allow you to append data to existing file. The output file is overwritten on every job run.
Excel data target
Excel data target allows you to write your data to Microsoft Excel files in xlsx format. The target produces a file with one sheet and a header. Formatting of data in the output file will follow formatting configured for columns in your Wrangler job.
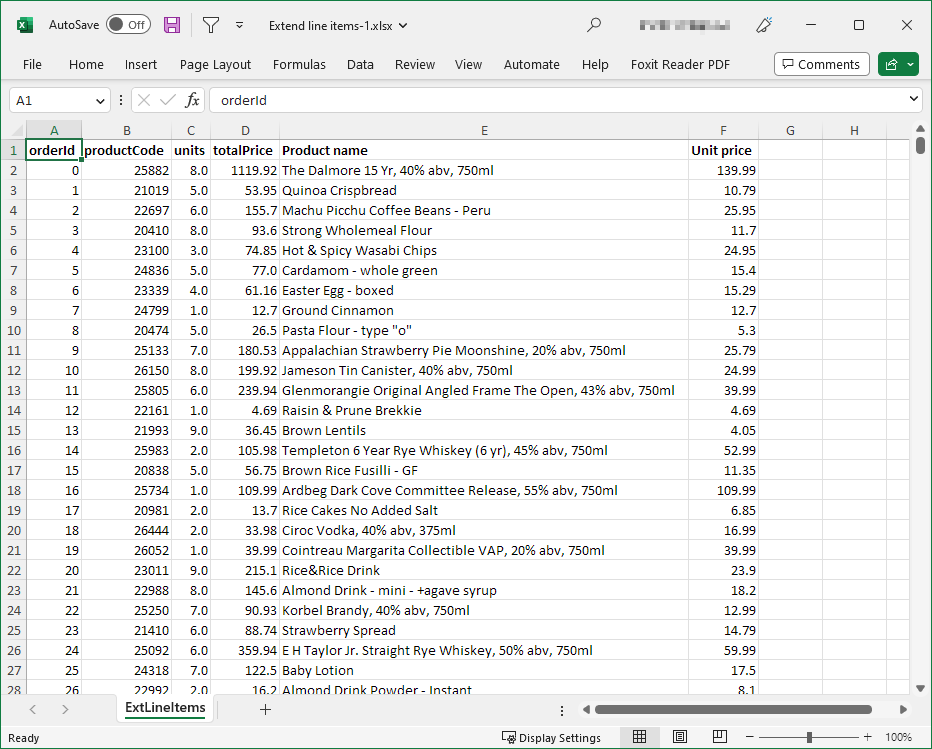
Figure 12. Sample Excel file create with CloverDX Wrangler
Excel data target configuration
Following settings are available for the Excel target:
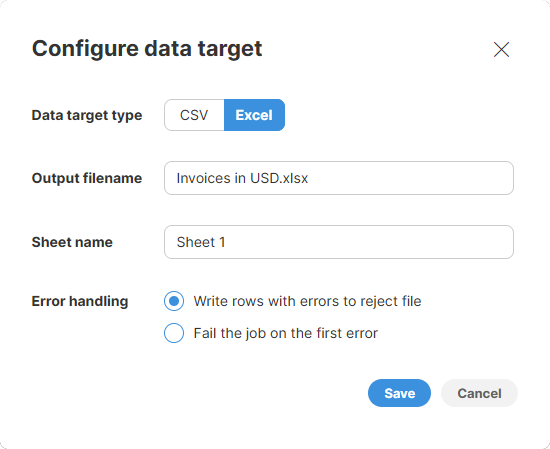
Figure 13. Excel data target configuration dialog
-
Output file name: name of the output file. The default value is the name of your Wrangler job with .xlsx extension.
-
Sheet name: name of the sheet to create in the output file. Note that Excel limits the length of the sheet name to 31 characters.
-
Error handling: determines what to do with rows that contain errors in any of their cells. Two options are provided:
-
Write rows with errors to reject file (default value): if selected, all rows that contain errors are written to a reject file. Reject file allows you to see the rejected rows as well as information about errors that caused those rows to be rejected (read more here). You can then see number of rows that were rejected on My Jobs page when job execution ends:
-
Fail the job on the first error: when an error is encountered when writing the file, the job is stopped and the error will be reported on My Jobs page:
-
Formatting of Excel files
The formatting of data in Excel output files depends on formats configured on columns in your data set. Wrangler will set the corresponding Excel format depending on display format for each column.
When saving to Excel file, Wrangler will save the complete value even if the formatting restricts the display of data. This is especially important for numbers which may be stored with higher precision than what is displayed in Wrangler preview.
For example, consider a value like 3.1415926535 written in Wrangler with decimal format set to #.### (i.e. three decimal places):

The column $formatted_constant was created as a duplicate of $constant_value column and then configured to show just three decimal places. The same is then replicated in Excel output in which complete value is stored and the formatting only applies during data display:
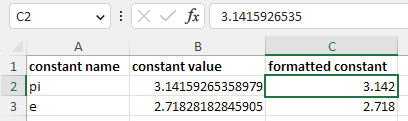
Note that the formats may not always be the same since Excel formatting and Wrangler formatting have slightly different capabilities.
Excel data target limitations
Note that some restrictions apply when working with Excel files. Some of the restrictions below are limitations of the Excel file format itself while others are technical limitations of the Excel data target in Wrangler.
-
You cannot write more than 1048576 rows into an Excel file. This is a limitation of the Excel file format. If you need to work with more data, you will need to use CSV data target.
-
You cannot have more than 16384 columns in the output. This is a limitation of Excel file format. Note that this is much higher than the default soft-limit for Wrangler columns - 1000 columns - so you are unlikely to reach this.
-
You can only create a single sheet in the output file using Wrangler.
-
You cannot append to the output file - the file is overwritten after each job run. This also means that you cannot use templates and add a sheet to them or modify them in any way.