ParallelPartition

| Short Description |
| Ports |
| Metadata |
| ParallelPartition Attributes |
| Details |
| Compatibility |
| See also |
Short Description
ParallelPartition distributes incoming data records among different CloverDX Cluster workers. The algorithm of the component is derived from the regular Partition component.
| Component | Same input metadata | Sorted inputs | Inputs | Outputs | Java | CTL | Auto-propagated metadata |
|---|---|---|---|---|---|---|---|
| ParallelPartition |  |  | 1 | 1[1] | [2] | [2] | |
[1] The single output port represents multiple virtual output ports. [2] ParallelPartition can use either a transformation or two other attributes (Ranges and/or Partition key). A transformation must be defined unless at least one of the attributes is specified. | |||||||
Ports
| Port type | Number | Required | Description | Metadata |
|---|---|---|---|---|
| Input | 0 | | For input data records | Any |
| Output | 0 | | For output data records | Input 0 |
Metadata
ParallelPartition propagates metadata in both directions. The component does not change priority of propagated metadata.
The component has no metadata templates.
The component does not require any specific metadata fields on its ports.
ParallelPartition Attributes
ParallelPartition has same attributes as Partition. See Partition Attributes.
Details
ParallelPartition distributes incoming data records among different CloverDX Cluster workers.
The algorithm of this component is derived from the regular Partition component. For more details about attributes and other component specific behavior, see the Partition component.
If the Ranges attribute is used for partitioning, the number of defined ranges must match the allocation of the following component. Use the and toolbar buttons to adjust the number of defined ranges:
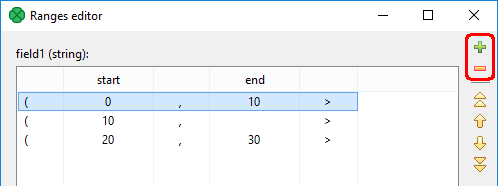
This component belongs to a group of Cluster components that allows the change from a single-worker allocation to a multiple-worker allocation. So the allocation of the component preceding the ParallelPartition component has to provide just a single worker. The allocation of the component following the ParallelPartition component can provide multiple workers.
![[Note]](../figures/note.png) | Note |
|---|---|
For more information about this component, see Chapter 41, Data Partitioning in Cluster. |
Compatibility
| Version | Compatibility Notice |
|---|---|
| 3.4 | The component is available since version 3.4. |
| 4.3.0-M2 | ClusterPartition was renamed to ParallelPartition. |